Amazon Web Services ブログ
Physical AIのためのデータ収集基盤を構築する①:模倣学習データの完全性を保証させるエッジシステム
みなさん、こんにちは。株式会社 APTO で Physical AI のデータ基盤を構築している田中です。

近年、ロボット向け VLA モデルの台頭により、AI 開発の成否は「学習データの品質」に強く依存するようになっています。 しかし、大容量かつ厳密な同期が求められるロボットの操作データを品質を落とさずに日々収集することは非常に困難であり、Physical AI 開発における最大のボトルネックとなっています。 このブログでは、同じ課題に直面するチームの参考となるよう、APTO 社がこの「データ収集」のハードルをどのように仕組み化して解決したのかを紹介します。
想定読者
- Physical AI / ロボティクス分野でデータ基盤を設計している方
- AWS 上で大量データのイベント駆動処理を構築しようとしている方
- スタートアップで少人数チームの MLOps を運用している方
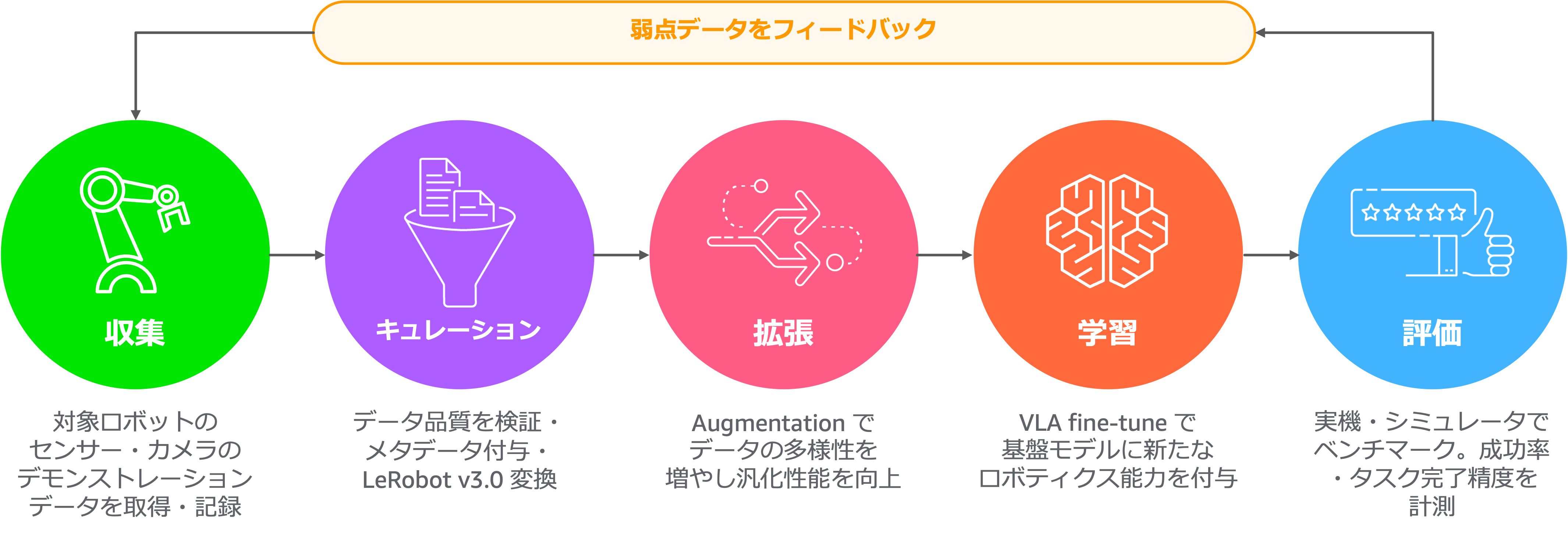
APTO が AWS 上に構築している双腕遠隔操作ロボット向けの Physical AI データ基盤について、下の図 1 でグリーンの ① 収集 の部分 — エッジ側で完全性をどう確定させ、Amazon S3 へどう引き渡しているか — を 3 章シリーズの第 1 章として解説します。データ基盤の全体像は「収集 → キュレーション → 拡張 → 学習 → 評価」という MLOps ループで構成されており、第 2 章ではクラウド側の自動キュレーションパイプラインに相当する ② キュレーション、第 3 章では ③ 拡張 および ④ 学習 への接続を扱う予定です。なお、本稿で扱う ① 収集ではエッジ側のチェックを「データの同期が取れているか」に絞っており、品質スコアリング・重複判定・PII検査・統計集計などのキュレーション工程はすべてクラウド側で実施する設計です。
図 1: MLOps ループ全体像 — 収集が本稿のスコープ
1. APTO と Physical AI
APTO は 2020 年 1 月設立、東京都千代田区にある約 40 名のスタートアップです (APTO 会社概要 2026時点)。「イノベーティブなアノテーションで AI 開発に変革を」を掲げ、AI データプラットフォーム harBest を軸に、画像・動画・3D (LiDAR)・自然言語・音声まで幅広い学習データ事業を展開するスタートアップです。近年は LLM 開発支援、RLHF、エージェント、RAG といった領域に加え、Physical AI のユースケースを増やしています。

その一環として、双腕の遠隔操作ロボット (bimanual teleoperation robot) からデータを集め、Vision-Language-Action (VLA) モデルのファインチューニングに供する自社基盤を AWS 上で開発しています。本基盤の中心は「収集 → 自動キュレーション → 学習」のループを効率よく回し続けるための仕組みであり、このブログではそのうち最も上流にあたる「収集」を扱います。
2. 背景と課題
Physical AI とデータ基盤の関係
Vision-Language-Action (VLA) モデルは、視覚と言語指示を統合してロボットの動作を生成する基盤モデルとして、研究と産業応用の両面で進展しています。Google DeepMind の RT-2、Physical Intelligence の π0 など、大規模 VLA モデルが相次いで発表されており、ファインチューニング向けの高品質データセットへの需要は今後も拡大が見込まれます。 ファインチューニングの成否は、モデルアーキテクチャの良し悪し以上に「投入するデータが安定した品質で揃っているか」に依存します。LLM の RLHF データセットに対する経験則と同じく、Physical AI でもデータおよびそれを提供するデータ基盤の完成度がモデル品質の上限を決める構造になりつつあります。
データを利用する上で直面する 3 つの構造的課題
Physical AI のデータパイプラインを運用しようとすると、次の課題に必ず突き当たります。
- 収集現場の不安定性: 双腕ロボットの遠隔操作中に PC が落ちる、USB が外れる、オペレータが途中で介入する、といった事象は日常的に発生します。1 件でも破損エピソードが混入すれば、その後の再現実験や学習指標の信頼性が損なわれます。
- 後段クラウドで品質判定するコスト: 1 エピソードが数百 MB〜数 GB に達するため、「ひとまず Amazon S3 にアップロードしてから品質判定する」設計では、転送・ストレージ・再ハッシュのコストが線形に積み上がります。
- 手動キュレーションの限界: 収集 → キュレーション → 学習 のループを回すには、目視確認・品質ラベル付け・Snapshot 構成といった工程を機械化しなければ、収集にキュレーションが追いつきません。
本基盤が目指す状態
これらを踏まえ、APTO の Physical AI データ基盤は次の状態を実装目標としています。
- 不完全なエピソードはエッジ側で除外し、Amazon S3 には「完成したエピソードだけ」が届く
- Amazon S3 への到着をイベント駆動で受け取り、人間の判断は Release 承認のみに限定する
-
レビュアーは、クラウド側のキュレーションパイプラインが算出する品質ゲート結果・データセット統計・lineage を見て承認 / 差し戻しを判断する (詳細は次回ブログで扱う)
-
- データの ID をハッシュから導出し、ingest を冪等にする (同じデータを何度取り込んでも結果が変わらない)
3. Physical AI のデータ収集が難しい理由
図 2: 収集からキュレーションまでのデータフロー全体像

模倣学習 (imitation learning) は、お手本となるデモンストレーションデータを再現するようにポリシーモデルを学習させる手法です。Physical AI の文脈では、教師データの候補として 人間のテレオペレーションで収集されたデータとシミュレーション環境で生成された合成データが挙げられます。現時点では動作や映像の自然さや接触の忠実度といった面でテレオペデータの方が品質が高いと考えられ、多くの場合は人間が遠隔操作したロボットの動作を再現するようにモデルを学習させます。VLA モデルのファインチューニングでは、この教師データとして用いる「人間のデモンストレーション」が一定品質で揃っていることが前提となります。 ところがロボットの生ログには、次の三つのノイズが必ず混入します。
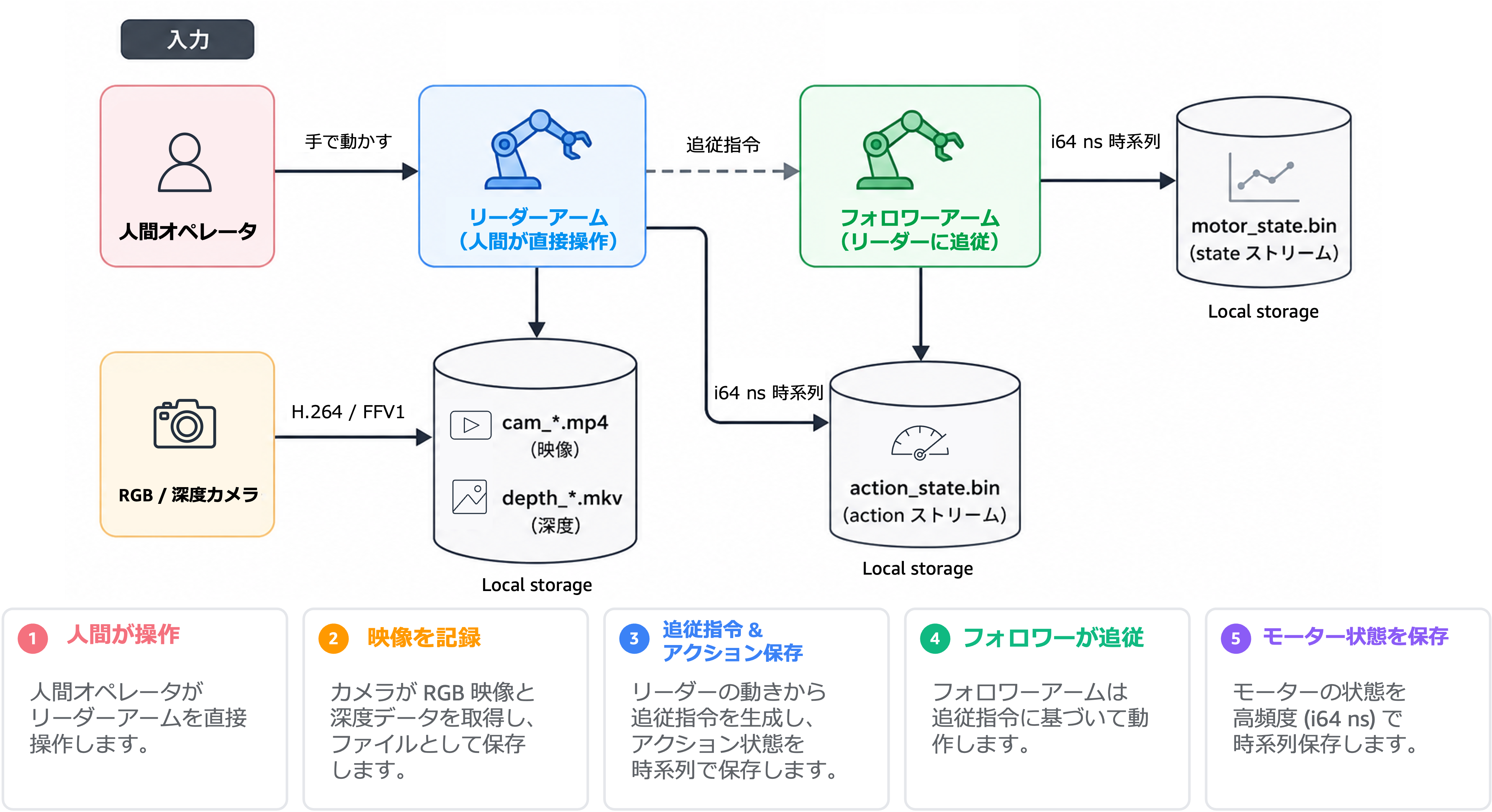
- アクションと状態の混在: 双腕遠隔操作では、人間が操作するリーダーアームと追従するフォロワーアームを別ストリームとして残さないと、
actionとstateが同一テンソルに混ざってしまいます。これは学習側のラベル設計を破壊します。 - 同期ズレ: カメラフレームとモータサンプルのタイムスタンプ差分が一定値を超えると、視覚と動作の対応関係が崩れます。本実装では WARNING / CRITICAL(2ms / 5ms)の二段階閾値で逐次判定しています。
- エピソードの欠損: 書き込み中に PC が落ちた、人間が途中で介入した、といった理由で不完全なエピソードが混じります。1 件の混入で再現実験の信頼性が失われます。
図 3: 双腕遠隔操作の Leader / Follower 構成

これらを後段のクラウドで除去する設計は費用対効果が悪く、Amazon S3 にアップロードしてから「不完全だった」と判明する経路では、転送と再ハッシュのコストが線形に積み上がります。本基盤ではエッジ側で完全性を確定させ、不完全なエピソードは S3 に渡さないことを設計の出発点としました。
4. 設計を貫く 3 原則
本基盤を貫く設計原則は次の 3 つです。データ品質を担保するためのルールとして先に定義し、そのうえでルールに則って AWSのサービスや機能を選定しています。
- Immutability: Episode / Snapshot / Batch は一度作ったら書き換えません。修正は新ハッシュで別エンティティを作り、
derived_fromで系譜を残します。 - Content-Addressed Storage: エピソードの ID はファイル群の決定論的ハッシュから導出します。同じデータを何度取り込んでも同じ ID になり、ingest が冪等になります。
- Event-Driven: 完了したエピソードの到着を S3 イベントで検知し、自動処理を駆動します。人間の判断は Release 承認のみに限定します。
5. 収集エンジンの 3 プロセス構成
図 4: sync-engine の 3 プロセス分離
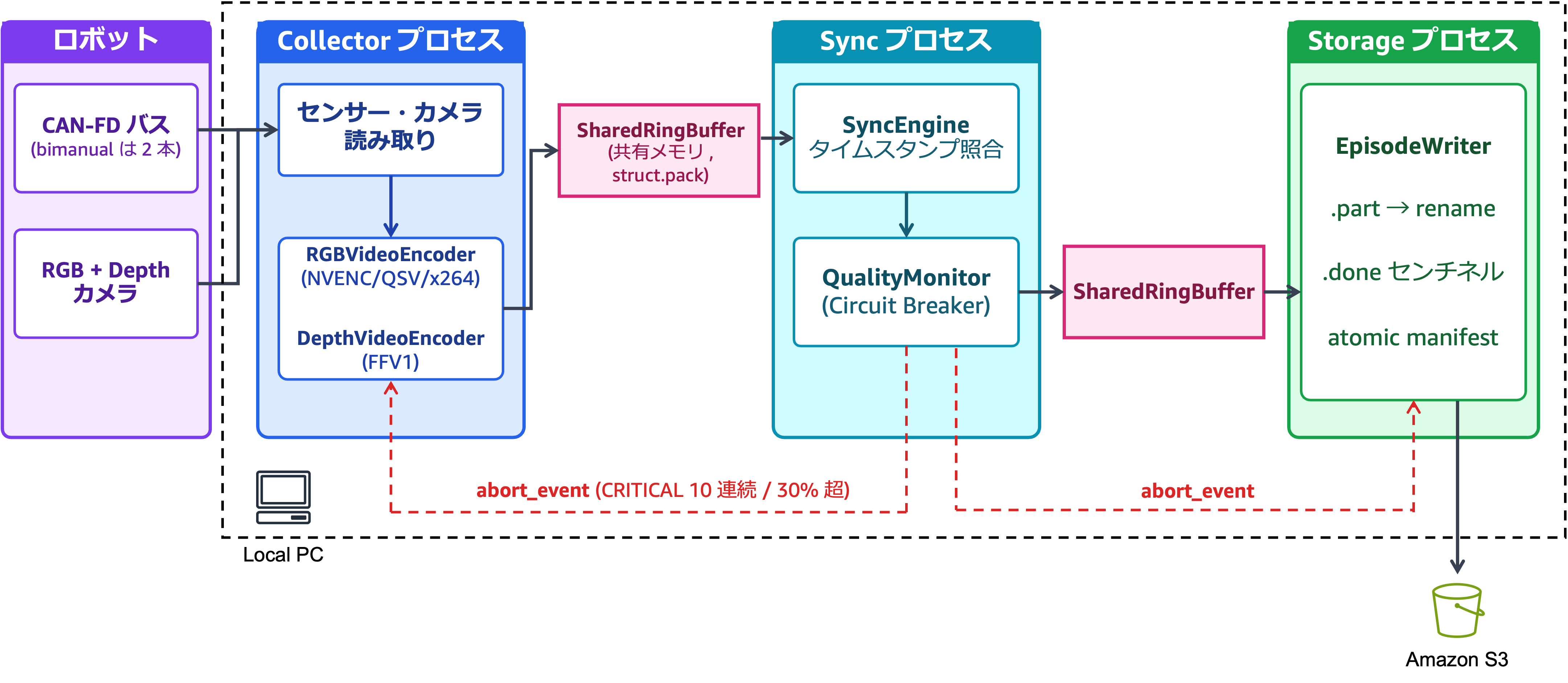
エッジ PC 側の収集エンジン (sync-engine) は、責務の異なる 3 つのプロセスを共有メモリ (SharedRingBuffer) で接続する構成を採っています。
- Collector プロセス: センサーとカメラからの読み取り、H.264 と FFV1 (深度) の動画エンコードを担当します。
- Sync プロセス: メタデータだけでタイムスタンプを照合し、同期品質を逐次判定します。
- Storage プロセス: motor_state.bin / sync_log.bin / events.jsonl などのバイナリファイルをディスクに書き出します。
この 3 プロセス構成は、後述する異常停止時の安全装置 (QualityMonitor) と直接結びつきます。Sync プロセス内で品質劣化を検知した時点で multiprocessing.Event を立て、Collector / Sync / Storage の 3 つを同時にグレースフル停止し、エピソードに .failed センチネルを置く流れです。
6. raw フォーマットの設計
現状のフォーマット選定と今後の方向性
エッジで保存する原本 (raw) のフォーマットは、学習で使う LeRobot v3.0 への変換前データを格納するレイヤです。Physical AI / ロボティクスで一般に検討される候補と評価ポイントを並べると次のようになります。
| 候補 | 評価ポイント |
|---|---|
| apto-raw-v5
(現行試行) |
変換前の物理層を可逆に残せる。当面の運用には十分だが標準ではない |
| MCAP
(Foxglove + ROS 2) |
スキーマと可視化が強い。ロスレス深度動画 (FFV1) や CAN-FD 生ログを 1 階層に同居させる運用を確立できれば有力候補 |
| HDF5 | 自己 記述型で扱いやすい一方、動画コーデックの選択肢が限定的、巨大単一ファイルが S3 のオブジェクト単位アップロード/部分取得と相性が悪いという課題 |
| Apache Arrow IPC | 列指向で学習側との親和性は高い。Stream Format で追記は可能だが、エピソード途中で異常終了した際の整合性保証が現時点のネック |
これらを踏まえ、現時点では自前の apto-raw-v5 を試行的に採用しています。標準フォーマット側で「ロスレス深度動画 + CAN-FD 生ログを 1 階層に同居させる」運用ノウハウが揃いきっていないため、まずは可逆性と運用容易性を優先した暫定解という位置づけです。 ただし、このレイヤのフォーマット選定は引き続き検討中で、Physical AI 周辺のフォーマット標準は流動的なため、将来的に MCAP などの標準フォーマットへ移行する可能性は残しています。いずれを採るにせよ、(1) 全タイムスタンプを int64 ナノ秒で統一する、(2) CAN-FD 生ログをそのまま保持する、(3) 深度動画をロスレスで保持する、という三点はフォーマット選定に依らず満たす方針です。これらは将来「キュレーションをやり直す」「別の特徴量を後付けで計算する」という要件に直接効いてきます。
クロック同期源
i64 ns で精度を確保しても、各センサーのクロック源が揃っていなければ同期判定そのものが意味を失います。本基盤では次の方針を取っています。
- カメラ: PTP (IEEE 1588) 対応の GigE Vision カメラを採用し、PC ホストを PTP マスタとして全カメラを同期。フレームには PC 受信時刻ではなくカメラ側ハードウェアクロックのタイムスタンプを正として保存します。
- モータ (CAN-FD): CAN フレーム自体はタイムスタンプを持たないため、CAN コントローラの SOF 受信タイミングを PC ホストの
CLOCK_MONOTONIC_RAWで打刻しています。CANコントローラのHWタイムスタンプを使う方法も考えられます。 - WARNING / CRITICAL 閾値の根拠: カメラフレーム間隔 33 ms (30 fps) に対し、サブフレーム精度を保つために WARNING 2 ms、CRITICAL 5 ms を設定。CRITICAL を超えるとフレーム内での視覚と動作の対応関係がずれ、模倣学習で扱えなくなります。
PTP 同期がない環境では NTP のミリ秒精度に劣化し、CRITICAL を超えるリスクが増えます。本基盤を別環境に適用する場合は、まずクロック同期源の選定が出発点になります。
7. 完全性をエッジで確定させる仕組み
収録中の電源断・プロセスクラッシュで、エピソードが「途中まで書かれた状態」になることは避けられません。問題はそれを後段が完成済みと誤認することです。誤認すると不完全なデータが学習データセットに混入します。エッジ側では「途中で壊れた状態のエピソードを下流に流さない」ことを最優先にしています。 エッジでは抽象度の異なる3つの層で完全性を担保します。
| 防ぐ失敗 | 仕組み | 失敗時のマーカー |
|---|---|---|
| レイヤ 1: ファイル単位 | ||
| 単一ファイルが書きかけのまま本来名で残る | アトミック書き込み: .part 拡張子で書き出し → fsync → atomic rename |
中間ファイルは .part のまま残る(本来名は存在しない) |
| レイヤ 2: エピソード単位 | ||
| 個々のファイルは完全だが、エピソード全体としては途中で中断している | .done センチネルによる完了判定。全ファイルが揃った後に .done センチネルを置く |
.done が存在しない |
| レイヤ 3: 意味的品質 | ||
| ファイルとしては完全だが、同期ズレで学習に使えない | 同期品質劣化時の安全停止 (QualityMonitor): QualityMonitor が閾値超過を検知 | .failed を置く |
後段(クラウド ingest や Storage プロセス側のスキャナ)は、この3つのマーカーだけを見て「完了 / 未完了 / 失敗」を判定します。中身のパースや SHA-256 検証は後段の責務として明確に切り分けています。 ファイルの存在だけを完了条件にしている理由は、復旧時の判断を静的検査だけで完結させたいためです。「特定ファイルが存在するか否か」だけで判定できれば、復旧ロジック自体を実質的に ゼロにできます。後述する Amazon S3 Event Notifications のフィルタ設計も、この原則の延長線上にあります。
全体シーケンス
まず初めに全体の流れを図示します。

- 各データファイルを .part で書き出し → fsync → atomic rename
- manifest.json を atomic write + 親ディレクトリ fsync
- 正常完了なら .done、異常停止なら .failed を touch
- RawUploadAgent が各ファイルを並列 PUT 後、manifest.json を最後に PUT して S3 Event を発火
ファイル単位のアトミック書き込み
個々のファイルは次の手順で書き出します。
.part拡張子で書き出す(例:cam_front.mp4.part)- 書き終わったら
fsync()でデータを物理デバイスに永続化する os.replace()で.partを本来名(例:cam_front.mp4)にアトミックに rename する- 親ディレクトリに対して
fsync()を呼び、ディレクトリエントリの変更も永続化する
この手順を守ることで、電源断が起きても「古い完全なデータが残っている」「新しい完全なデータが置かれてい る」「.part のまま残っている」のいずれかにしかならず、本来名で半端なファイルが見える状態は発生しません。manifest.json も同じ手順で書き出します。
また、エッジストレージ は NVMe SSD + ext4 (data=ordered) を採用しています。ext4 の data=ordered モードでは、データブロックがジャーナル commit より先にディスクへ書き出されることが保証されます。このため、fsync() + os.replace() の組合せでクラッシュ後も「古い完全なデータ」または「新しい完全なデータ」のどち らかが必ず観測されます。これは アトミック書き込みが成立する前提条件です。NFS / FUSE 等にファイルシステムを変更する場合、アトミック書き込みが破綻する可能性があるため、必ず再評価が必要です。
エピソード単位の完了判定
すべてのファイルが揃った時点で、エピソードディレクトリ直下に .done を touch します。途中で中断した場合は .done を置かないか、QualityMonitor が .failed を置きます。
完了検知は、.done と manifest.json の両方が揃っているかだけで判断します。中身のパースや整合性チェックはクラウド側 ingest の責務として後段に切り分けています。
意味的品質を守る安全装置 (QualityMonitor)
ファイルが完全に書けても、収録中の同期品質が劣化していれば学習には使えません。Sync プロセスはカメラフレームと最近傍モータサンプルのタイムスタンプ差分(同期ズレ)を逐次監視しています。この差分の時系列は原本中の sync_log.bin に保存され、後段の品質ゲートでも参照できます。
QualityMonitor が .failed を置く判定条件は次の二つです。
- CRITICAL レベルのドリフトが一定フレーム数連続する
- 観測ウィンドウ内で CRITICAL の割合が一定割合を超える
いずれかを満たした時点で、3 プロセス全体(Sync / Storage / Camera)をグレースフル停止し、エピソードに .failed センチネルを置きます。これにより、品質が劣化したフレームが含まれるエピソードはクラウ ドに渡る前にエッジで除外されます。
8. Amazon S3 へのアップロード
manifest.json を最後に PUT する設計
RawUploadAgent は完了したエピソードのディレクトリを 1 ファイルずつ Amazon S3 raw バケットにアップロードします。ここで重要なのは、manifest.json を最後に PUT することです。
理由はクラウド側の S3 Event Notifications との接続にあります。1 エピソードから 8 オブジェクト前後が生成されますが、すべてに対してイベントを発火させると下流の Amazon SQS キューが 8 倍に膨らみます。さらに、まだアップロード途中の状態で Worker が S3 を読みに行くと、ファイル不一致による偽の IntegrityError が DLQ に積まれてしまいます。
そこで、(1) S3 Event Notifications 側でフィルタを filter_suffix = "/manifest.json" に絞り、(2) manifest.json は他の全ファイルの PUT が完了してから最後に置く、という二段の制約で「完了したエピソード 1 つに対して SQS メッセージ 1 つ」を成立させています。 この設計が成立するのは、S3 Event Notifications がオブジェクトキーの prefix / suffix フィルタをネイティブにサポートしているからです。Terraform での設定はほぼ次の 1 ブロックに収まります。
resource
"aws_s3_bucket_notification" "raw"
{
bucket = aws_s3_bucket.raw.id
queue {
queue_arn = aws_sqs_queue.s3_events.arn
events = ["s3:ObjectCreated:Put"]
filter_suffix = "/manifest.json"
}
depends_on = [aws_sqs_queue_policy.s3_events]
}filter_suffix を /manifest.json に固定するだけで、エッジ側が manifest.json を最後に PUT した瞬間にのみ SQS メッセージが 1 件キューに入る関係が S3 側で完結します。 実装は concurrent.futures.ThreadPoolExecutor で並列 PUT し、as_completed() で全 future の完了を待ってから manifest.json を PUT します。1 つでも失敗していれば例外を伝播させ、.failed を残してエピソード全体を破棄します。
from
concurrent.futures import ThreadPoolExecutor, as_completed
def upload_episode(episode_dir:
Path, bucket: str, key_prefix:
str) -> None:
data_files = [f for f in
episode_dir.iterdir()
if f.name not in
{"manifest.json", ".done"}]
with ThreadPoolExecutor(max_workers=8) as pool:
futures = [pool.submit(_put_with_checksum, f, bucket,
f"{key_prefix}/{f.name}") for f in data_files]
for fut in
as_completed(futures):
fut.result() # raise on failure → episode を破棄
# 全データファイル PUT 完了後に manifest.json を最後に PUT
# → S3 Event Notifications の filter_suffix="/manifest.json"が発火
_put_with_checksum(episode_dir / "manifest.json", bucket,
f"{key_prefix}/manifest.json")_put_with_checksum は boto3 の put_object(ChecksumAlgorithm="SHA256") を呼び、S3 の Additional Checksum 機能でサーバ側でも SHA-256 を再計算させてオブジェクトメタデータに保存します。Worker 側の再計算検証と組み合わせ、データ整合性は二重に担保しています。
.tar でまとめない理由
今回はエピソードを .tar でまとめずに、ディレクトリ構造をそのまま Amazon S3 のキー階層に写し取る方針を採っています。tar 一括 PUT 案と個別 PUT 案を精査した結果、コスト差は小さく(現状 8 ファイル/エピソード規模で損益分岐は約 43 ファイル)、判断は技術観点で決まりました。個別 PUT を選んだ主な理由は次の通りです。
- 後段 Stage の非対称なアクセスパターン: 映像品質判定は動画のみ、学習は Parquet のみを必要とします。個別 PUT なら必要なファイルだけ GET できますが、tar 化すると毎回全体を GET して展開する必要があり、特に GPU ノードで I/O 待ちが発生するのは設計として不適切です。
CopyObjectによる stream-copy 最適化が崩れる: ColdConvertStage では動画を raw から cold へCopyObjectで転記し、ECS Worker の CPU・帯域コストをゼロに抑えています。これは個別ファイルが独立した S3 オブジェクトとして存在することが前提です。- tar の「全か無か」性質との不整合: 部分破損で全体が読めなくなる、Range Request で部分読みできない、Glacier 復元で毎回全体を取り出すことになる、IAM / KMS 粒度がファイル単位で切れない、といった問題が積み重なります。
なお tar 形式そのものを否定しているわけではなく、学習配布用の WebDataset 形式や Glacier Deep Archive への長期アーカイブなど、raw アップロード経路とは別レイヤーで tar 化する価値がある用途は存在します。
9. まとめと次回予告
このブログでは、Physical AI のデータ基盤において「完成したエピソードだけを AWS に渡す」状態をエッジ側でどう作るかを解説しました。要点は次の三点です。
- 自前フォーマット apto-raw-v5 を採用: i64 ns タイムスタンプ・CAN 生ログ・ロスレス深度を 1 階層で保持しています。MCAP / HDF5 / Apache Arrow IPC のいずれでもこの組合せを単独では満たせなかったためです。
- 完了判定をファイル存在のみに統一:
.doneとmanifest.jsonの両方が揃ったときだけ完了とみなす原則を採り、状態機械の複雑化を避けました。これがクラウド側のイベント駆動設計に直結します。 - manifest.json を最後に PUT: Amazon S3 Event Notifications を「エピソード完了 = 1 通知」という対応関係に整理しました。
Physical AI のデータパイプラインを長く回し続けるには、「機械的にやれる工程は全部自動に寄せ、人間の判断を Release 承認だけに集中させる」ことが鍵となります。エッジ側で完全性を確定させる本稿の設計は、その自動化を成立させる土台です。 第 2 章では、この manifest.json 到着イベントを起点に動く AWS 側のキュレーションパイプラインを扱います。Amazon S3 → Amazon SQS → Amazon ECS Fargate Worker のイベント駆動 ingest、Episode / Snapshot / Batch の 3 層モデル、9 サブステップの構造化キュレーションと 2 階層品質ゲートが中心です。続く第 3 章では、データ拡張と VLA ファインチューニングへの接続、シミュレーション環境との統合、マルチロボット対応の方向性を予告編としてお届けします。 同じような課題に取り組まれているスタートアップの参考になれば幸いです。
We are hiring!!
APTOは、AIやPhysical AI領域のデータに特化したサービスを提供しています。 技術の実装を進めたい方、研究開発に興味がある方などは、下記採用ページからエントリーください! https://apto.co.jp/careers/
著者プロフィール
 |
田中 達也 (Tatsuya Tanaka)
APTOにてPhysical AIやロボティクス領域のデータパイプライン開発、およびUI構築をメインに担当しているAIエンジニアです。データの同期やマルチモーダルデータ管理など、AI活用に向けたデータ基盤の設計・開発に従事しています。趣味は競技プログラミングと陸上観戦。学生時代は陸上一筋でしたが、現在はもっぱら見る専門です。 |
 |
遠藤 俊策 (Shunsaku Endo)
ポジション: Co-founder / AI Engineer バンタンゲームアカデミーで、学内の審査会で数々の賞を受賞。その後、AI開発にも興味を持ち2020年1月にAPTOを共同創業。現在は、APTOのCDOとして開発とビジネス双方を管理。 GitHubアカウント: synsax(https://github.com/synsax) |
 |
黒澤 蓮 (Ren Kurosawa) は AWS Japan のソリューションアーキテクトで、Startup 業界のお客様を中心にアーキテクチャ設計や構築をサポートしています。データアナリティクスサービスや機械学習の領域を得意としています。将来の夢は宇宙でポエムを詠むことです。 |