Amazon Web Services ブログ
Category: Advanced (300)

Amazon SageMaker のカスタムサブスクリプションワークフローによるデータガバナンスの加速
本記事では、Amazon SageMaker のサブスクリプションリクエスト承認を自動化するカスタムワークフローを紹介します。AWS Lambda、Amazon EventBridge、Amazon SNS を組み合わせたイベント駆動型のサーバーレスアーキテクチャにより、ガバナンスを維持しつつ機微でないデータセットへのアクセスを迅速化できます。

Amazon SageMaker Catalog を利用するガバナンスチーム向けメール通知の自動化
Amazon SageMaker Catalog で発生するイベントを中央ガバナンスチームに自動通知する仕組みを、Amazon EventBridge、AWS Lambda、Amazon SNS、Amazon SQS を組み合わせて構築する方法を紹介します。プロジェクト作成や資産公開といった重要なイベントをリアルタイムで捕捉し、メールアラートとして届けることで、組織のガバナンス標準をスケールしながら維持できます。

Amazon EVS で Windows Server ライセンスが利用可能に: ステップバイステップガイド
Amazon EVS で Microsoft Windows Server ライセンスが利用可能になりました。BYOL または vCPU 時間単位の AWS 提供ライセンスの 2 つのオプションから選択でき、EVS 環境内で Windows Server VM を柔軟に運用できます。本記事では、vCenter コネクタの作成からライセンスエンタイトルメントの設定、KMS サーバーによるアクティベーションまでの手順を説明します。

Amazon RDS for SQL Server における追加ストレージボリュームによるストレージの改善
この記事では、Amazon RDS for SQL Server の追加ストレージボリューム機能を使用して、これらの一般的な課題に対処する方法と「追加ストレージボリュームの64 TiB を超える容量の拡張 」「動的な一時ストレージの管理 」「カスタマイズされた IOPS 設定によるパフォーマンスの向上 」「ストレージクラスの選択によるコスト削減 」「トランザクションログの分離 」「マルチテナントストレージの分離の実装」の 6 つの主要なユースケースの実装方法を学びます。
Amazon OpenSearch Service、FAISS エンジンでのベクトル検索トラブル対処の考え方:新規ベクトルデータの投入が不安定、または失敗する場合
はじめに Amazon OpenSearch Service を使用したベクトル検索では exact k-NN […]
Amazon OpenSearch Service、FAISS エンジンでのベクトル検索トラブル対処の考え方:検索レイテンシの増加が問題になっている場合
はじめに Amazon OpenSearch Service を使用したベクトル検索では exact k-NN […]

Amazon CloudFront のパブリックオリジンからプライベート VPC オリジンへの移行
この記事では、さまざまな戦略を使用して Amazon CloudFront のパブリックオリジンを Amazon Virtual Private Cloud (Amazon VPC) オリジンに移行する方法を紹介します。また、クロスアカウントで VPC オリジンを使用することで、セキュリティを最優先としたアーキテクチャをサポートすることもできます。

AWS Security Agent 徹底解説: 自動ペネトレーションテストのためのマルチエージェントアーキテクチャ
AWS Security Agent に組み込まれた自動ペネトレーションテストのマルチエージェントアーキテクチャについて解説します。従来は数週間を要していたペネトレーションテストを、専門化された AI エージェント群の連携により自動化し、認証処理、ベースラインスキャン、多段階探索、アサーションベースの検証までを一貫して実行します。単一の脆弱性検出にとどまらず、複数の脆弱性を組み合わせた複雑な連鎖攻撃の検出・検証まで実現する仕組みを紹介します。

Amazon EMR Serverless のベストプラクティス 10 選
Amazon EMR Serverless のパフォーマンス、コスト、スケーラビリティを最適化するためのベストプラクティス 10 選を紹介します。アプリケーション設計、ワーカーの適正化、Graviton プロセッサの活用、ストレージ選択、マルチ AZ 構成など、効率的なデータ処理パイプラインの構築に役立つ実践的な推奨事項をまとめています。
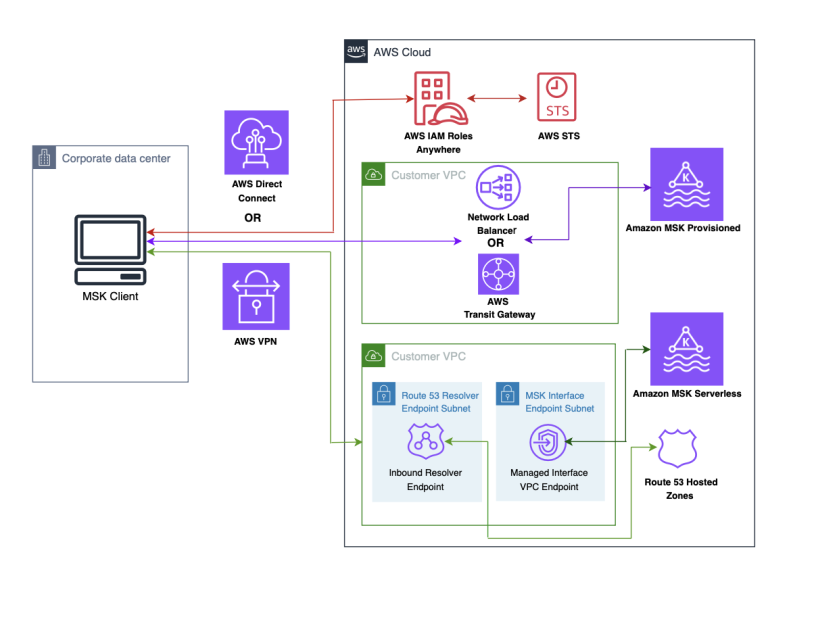
IAM Roles Anywhere を使用して AWS 外の Kafka クライアントから Amazon MSK にセキュアに接続する
本記事では、AWS IAM Roles Anywhere を使用して、AWS 外で動作する Kafka クライアントから Amazon MSK クラスターにセキュアに接続する方法を紹介します。X.509 証明書による一時的なセキュリティ認証情報の取得により、長期認証情報の管理が不要になり、セキュリティ体制を強化できます。