亚马逊AWS官方博客
Multi-Agent 架构在零售供应链运营中的实践:贯穿数据、洞察与行动
摘要:供应链是零售企业最核心的竞争壁垒之一,而决策效率的瓶颈往往不在数据基础设施,而在从数据到洞察、从洞察到行动之间的链路。本文探讨如何通过 Agentic AI 系统性地打通这条链路——利用 Multi-Agent 架构、让供应链数据自动被查询、被理解、被转化为行动,实现从 data-informed 到 data-driven 的跨越。文章包含架构设计、关键技术选型,以及一个完整的渠道履约分析场景演示。
目录
一、供应链决策的全链路挑战
供应链是零售和消费品企业最核心的竞争壁垒之一,也是运营复杂度最高的领域。供应链决策的特点是高频、多节点、强耦合, 而且每个决策都有可量化的成本度量。库存周转快一天、缺货率降一个百分点、物流异常早发现一小时——在千万级 SKU 和数十亿营收的规模下,这些改善直接影响成本结构、客户体验和市场响应速度。而这些改善的前提,是决策质量——在正确的时间,基于准确的信息,做出正确的判断。
“数据驱动”是供应链转型中最常被提及的目标。经过多年数字化建设,大多数企业的数据基础设施已经逐渐就位——从 ERP、WMS、TMS 到数据湖和可视化看板,数据采集和集中一直是过去十年的主要方向。其中的主流方案是控制塔(Control Tower):一个集中的 Dashboard,汇聚多源数据,提供可视化看板和告警。但在供应链这种多方参与的场景中,经销商和渠道伙伴各自运营独立系统,数据格式和接入程度参差不齐,”完全集中”始终是一个理想状态——实际中,数据格式、更新频率和接入深度的差异意味着总有一部分数据无法真正进入数据湖。控制塔解决了”数据可见”的问题,但本质上仍是 data-informed(数据辅助决策)——分析能力在建设阶段就固化了,只能展示不能推理,迭代周期以周甚至月计。真正的 data-driven(数据驱动决策)要求数据自动被查询、被分析、被转化为行动,而不是停留在 Dashboard 上等人来看。
数据驱动的完整链路是:采集 → 查询 → 洞察 → 行动。过去的数字化解决了采集问题,但从查询到行动的链路仍然高度依赖人工——运营团队用 Excel 做分析、用邮件推动行动,数据湖里的数据并没有真正流动起来。我们把瓶颈归纳为三部分:查询壁垒、洞察缺位、行动脱节。
1.1 查询壁垒:数据可见,但查询不易
数据分散在多个系统中——有些已经进入数据湖,有些仍在源系统。无论哪种情况,运营团队要用它回答一个业务问题,都面临实际的障碍:
- SQL 技能门槛:查询数据需要了解表结构、字段含义和 SQL 语法,这不是运营人员的技能栈。每次分析需求都要依赖数据团队,排期以天计。
- 业务口径不统一:”发货完成率”在不同报表、不同团队中可能有不同定义。查询前需要先对齐口径,否则数据正确但结论错误。
- 多表关联复杂:一个看似简单的分析问题(如”上月各渠道的履约表现”)往往涉及 3-5 张表的关联查询,手工编写容易出错。
有研究显示,即使数据基础设施已经就位,供应链团队仍然花 60-70% 的时间在数据查询和格式对齐上,真正用于分析和决策的时间非常有限。
1.2 洞察缺位:从数据到答案的距离太远
即使数据能够获取,也只是数据表或者指标,不是业务洞察。
举一个典型场景:运营团队需要做”与去年同期的发货进度比较与原因分析”。这个看似简单的需求,实际上需要:
- 从数据库提取多季订单与发货数据
- 按品类、渠道等维度对齐统计口径
- 量化差异(哪些品类落后、落后多少)
- 识别原因(是节奏不均导致某月缺货?还是某渠道伙伴发货延迟?)
- 输出对比数据、归因结论及优化建议
这不是一条 SQL 能解决的,也不是一个 Dashboard 能展示的。传统 BI 报表和控制塔能告诉你”华北区库存周转天数 68 天”,但不会主动告诉你”这比去年同期多了 12 天,主要由户外装备品类拖累,建议跨区调拨”。从数据到洞察之间,隔着大量的人工分析工作。
1.3 行动脱节:从洞察到执行存在断层
分析完成后,从洞察到行动之间仍然有一段距离。比如: 分析师发现华北区户外装备滞销,但要推动跨区调拨,需要:评估目标区域的消化能力、计算物流成本、协调仓储资源、获得审批。这些环节目前依赖邮件、会议和人工协调,响应周期以天甚至周计。
这三层瓶颈不是孤立的——查询壁垒导致洞察延迟,洞察缺位导致行动滞后,最终形成一个决策迟滞的恶性循环。 在快速变化的市场中——促销窗口稍纵即逝、季节性品类的生命周期以周计——决策延迟的代价是实实在在的库存积压和错失的销售机会。 这正是Agentic AI 可以系统性改善的方向。
二、为什么是 Agentic AI——它改变了什么
Agentic AI 改变的不是数据基础设施, 而是数据到决策之间的推理链路:把原来由人完成的查询、分析、归因、方案准备自动化了。这正是从 data-informed 走向 data-driven 的关键一步。
Agentic AI 是控制塔的下一代演进——从”看数据”变成”问数据”,从”被动展示”变成”主动推理”,让数据真正驱动决策和行动,带来的优势包括:
- 释放更多的分析需求:回答一个供应链问题的最小单元从”一个分析师 + 半天”变成”一句话 + 30 秒”。提问成本的大幅降低意味着更多问题会被问到、被分析、被跟进——决策覆盖面从”只看关键指标”扩展到”任何值得关注的异常都能被追问”。
- 推理链路可复现:Agent 的分析过程是结构化的——同样的问题、同样的数据,会产生一致的分析路径。这意味着分析结论可以被审计、被迭代,不再完全依赖个人经验。
- 从被动应答到主动监控:当前阶段 Agent 响应用户提问,但同样的分析能力可以用于主动监控——定期扫描关键指标,异常时自动推送分析结果,而不是等人来问。
更重要的是,Agentic AI 可以系统性地回应前面提到的三层决策瓶颈:
| 决策瓶颈 | 控制塔的做法 | Agentic AI 的做法 |
| 查询壁垒 | 需要 SQL 技能和数据工程支持 | Agent 自动将自然语言转为 SQL 查询 |
| 洞察缺位 | 展示预定义指标 | Agent 主动做趋势分析、异常检测、归因 |
| 行动脱节 | 洞察停留在报告,行动依赖人工协调 | Agent 将洞察转化为行动,可自动触发工作流 |
三、参考方案架构与设计
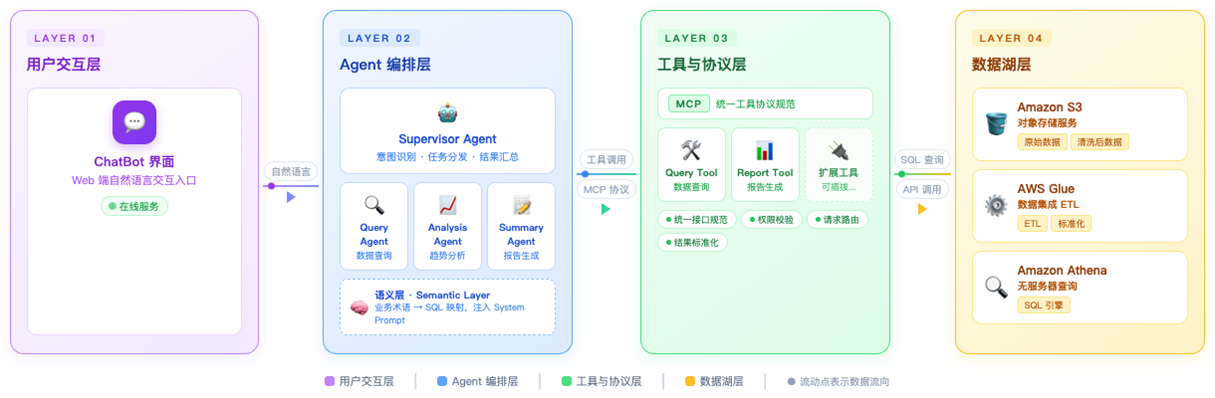
本文聚焦零售供应链的日常运营分析场景,展示如何通过 Multi-Agent 架构建立数据驱动的决策闭环——从数据查询、异常归因到行动准备的完整链路。以下是参考设计和架构图:
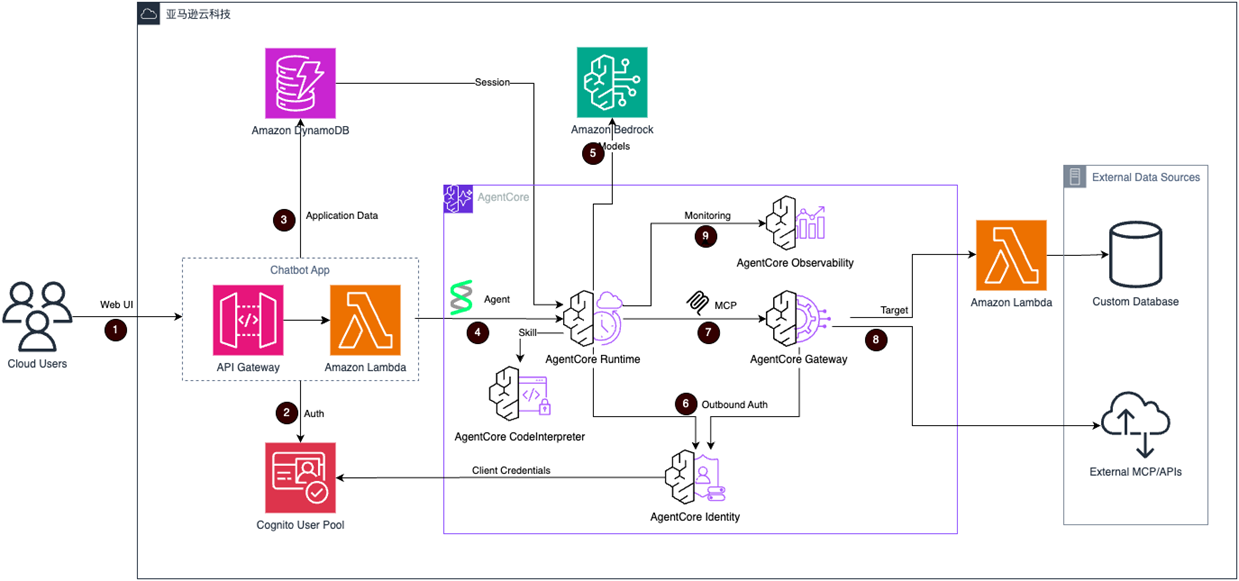
[图1] |
[图2] |
① 用户访问:聊天机器人的前端和后端通过 API Gateway 与 Lambda 函数集成的方式进行部署。
② 身份验证:用户身份验证通过 Amazon Cognito 用户池来处理。
③ 数据存储:与应用程序相关的数据,包括聊天记录和配置信息,存储在 Amazon DynamoDB 中。
④ 核心 Agent 应用:主要的 Agent 应用基于 Strands 框架构建,并部署在 AgentCore Runtime 运行环境中。
⑤ AI 模型服务:大型语言模型能力由 Amazon Bedrock 提供。
⑥ 身份管理:所有身份验证流程以及第三方身份验证/API 密钥管理均通过 AgentCore Identity 服务来处理。
⑦ 外部数据访问:访问外部数据源的工具主要通过 AgentCore Gateway 并采用模型上下文协议(MCP)方式来提供。
⑧ 网关集成:AgentCore Gateway 支持两种目标类型:(a)API 目标:用于外部 API 集成. (b) Lambda 目标:用于自定义数据源(例如数据库)
⑨ 监控与可观测性:系统监控和可观测性通过 AgentCore Observability 服务来实现。
下面逐层展开:
3.1 交互层
用户通过 Web UI 发起对话请求,流量首先进入 API Gateway,由后端 Amazon Lambda 处理前端逻辑与请求路由。在请求进入核心 Agent 流程之前,Amazon Cognito User Pool 负责完成用户身份认证,确保每一个会话请求都经过合法性校验,从安全边界上隔离未授权访问。
3.2 Agent 编排层:Supervisor-Workers
经过认证的请求进入 AgentCore Runtime,这是基于 Strands 框架构建的核心 Agent 运行环境。Amazon DynamoDB 承担会话上下文(Session)与Agent配置数据的持久化存储,保证多轮对话的连贯性。
供应链数据分析涉及多种差异很大的能力——SQL 生成、业务归因、报告撰写、行动方案准备等。我们发现,如果将这些能力集中到一个 Agent 的 System Prompt,随着 Prompt 膨胀,各项任务的准确率都会下降——尤其是 SQL 生成,对 Prompt 中的噪声非常敏感。
因此我们采用 Supervisor-Workers 架构,让每个 Agent 专注一件事:
- Supervisor Agent:理解用户意图,根据问题复杂度编排调用, 例如:简单查询走 Query → Summary,分析类问题走 Query → Detail → Research → Summary → Action
- Query Agent:将自然语言转为 SQL,通过 MCP 调用数据源执行基础查询和同比对比
- Detail Agent:在 Query Agent 发现异常后,按品类、时间、区域等维度做多维度下钻查询
- Research Agent:基于下钻数据,从多个方向排查异常根因
- Summary Agent:将分析结果组织为结构化的业务报告
- Action Agent:将分析洞察转化为可执行的行动(如发送通知、创建工单、生成审批材料等)
这些 Worker Agent 恰好对应了前面提到的决策链路:Query Agent 和 Detail Agent 消除查询壁垒,Research Agent 和 Summary Agent 填补洞察缺位,Action Agent 弥合行动脱节。
拆分后,每个 Agent 的 System Prompt 可以做到精简且专注。但拆分带来的一个设计问题是 Agent 间的上下文传递。每个 Worker Agent 只看到自己的输入和输出,不共享对话历史。我们让Supervisor 承担”上下文中枢”——它持有完整的对话状态,调用每个 Worker 时将前序 Agent 的输出作为 context 注入。这比所有 Agent 共享一个巨大的对话历史要高效得多,也避免了不必要的 token 消耗。
另一个值得一提的设计选择是配置驱动。所有 Agent 的定义(System Prompt、模型、工具列表)通过来自于DynamoDB的原子化数据组成YAML 配置管理,不硬编码在代码中。调整一个 Agent 的行为,修改配置即可,不需要重新部署。以下是一个简化的配置示例:
Supervisor 根据问题类型选择不同的编排路径,简单查询直接返回,复杂分析则按”基础数据 → 多维下钻 → 根因研究 → 总结建议 → 行动准备”逐步深入。新增一个分析维度或调整查询逻辑,只需要修改对应 Agent 的 system_prompt。
Sub-agent通过下面的方式作为工具被supervisor所调用
这种形式把”多智能体协作”问题降维为”工具调用”问题。在此模式下,Supervisor Agent 无需感知子 Agent 的内部实现,只需通过统一的 Tool 接口完成调用,从而实现模块低耦合。各 Sub-Agent 作为自治单元独立演进,新增或升级某一领域能力时无需改动编排逻辑,扩展成本极低。并且本模式与 MCP 协议规范天然对齐,将SubAagent 与数据库查询、外部 API 等工具置于同一抽象层,可复用权限校验、请求路由与链路观测,驾驭复杂的 AI 编排
值得注意的是,这些编排规则本身就是行业经验的结构化表达——异常阈值设为 5% 而非 10%、下钻时先看渠道再看品类、什么情况下触发根因分析,这些判断来自供应链运营团队的实际经验,而非 Agent 自行推断。配置驱动的设计让这些经验可以被显式管理和持续迭代。
3.3 语义层:让 Agent 理解业务语言
在我们的经验中,Agent 最容易出错的地方,不是 SQL 语法,而是在于如何真正理解业务术语。”滞销品”在不同企业有不同定义——可能是”90 天零动销”,也可能是”库存周转天数 > 90″。如果不显式告诉 Agent,它会基于通用语义理解生成 SQL,语法正确但业务上不可用。
我们在 Query Agent 的 System Prompt 中注入语义层(Semantic Layer), 这是一份业务术语到 SQL 表达式的映射:
这段配置看起来简单,但在实践中我们发现它是整个系统对于业务理解最有价值的部分——不是代码,而是企业业务知识的结构化沉淀。在供应链领域,语义层的价值尤为突出——同一个指标在不同企业、不同渠道、甚至不同团队中可能有不同定义,而这些定义直接决定了分析结论的可信度。语义层的质量是整个系统业务准确性的天花板。有了语义层,运营人员说”帮我看看哪些是滞销品”,Agent 能按企业自己的标准去查询,而不是推测一个通用定义。
语义层不是一次性工作。业务定义会变、新指标会加入、查询规则会更新。我们将语义层作为配置的一部分管理,业务团队提出定义变更时,更新映射规则即可,不需要改代码。这降低了维护门槛,也让业务团队能直接参与语义层的演进。
3.4 工具与协议层:用 MCP 解耦数据源
Agent 需要访问数据,但我们不希望把数据库连接逻辑硬编码在 Agent 里。供应链场景下数据源的变化是常态——当前阶段查询 Athena 中的库存数据,下一阶段可能需要接入渠道伙伴的 API,之后还可能更换查询引擎。数据源的复杂度尤为突出——品牌方自有系统的数据可能已经进入数据湖,但渠道伙伴的数据接入程度各不相同,且随业务关系变化而调整。
MCP在Agent 和数据源之间提供了一层标准化的抽象。Agent 不直接连数据库,而是通过 MCP 调用”工具”, Agent 只需要知道”我可以用这个工具执行 SQL”,不需要关心底层是 Athena、Redshift 还是 MySQL。
Agent 编排层通过 MCP 协议向 AgentCore Gateway 发起工具调用请求,Gateway 作为统一的工具代理层,支持多类目标路由。AgentCore Identity 负责管理所有出向认证(Outbound Auth),包括第三方 API Key、OAuth Token 等凭证的安全存储与动态注入,确保工具调用过程中的身份合规性,Agent 无需在代码中硬编码任何密钥。
这种解耦在实践中已经验证过价值:项目中查询引擎从一个数据仓库方案迁移到云原生查询服务,涉及 SQL 方言、连接方式和认证机制的全面变更。因为 Agent 层和数据层通过 MCP 解耦,迁移时无需修改任何 Agent 代码——只是替换了 MCP Server 的实现。如果没有这层抽象,所有涉及数据查询的 Agent 逻辑都要重写。
实际系统中不只有一个数据源。我们设计了统一的 MCP 管理器,支持同时连接多个 MCP Server(数据查询、Web 搜索、报告生成等),每个 Server 有独立的认证方式。Agent 在配置中声明需要哪些工具,系统启动时自动建立连接并注入。扩展能力变得很轻量——接入一个新数据源,部署对应的 MCP Server,配置中加一行引用即可。
3.5 数据湖层
将 Agent 发出的查询请求转化为针对数据的 SQL 调用;AWS Glue 完成原始数据的 ETL 清洗与标准化;Amazon S3 分层存储原始数据与处理后数据,构成完整的数据湖查询链路。
四、场景演示:从提问到洞察的完整链路
为了展示 Multi-Agent 架构如何将前面提到的设计理念落地,我们用一个完整的分析场景来演示系统的工作过程。
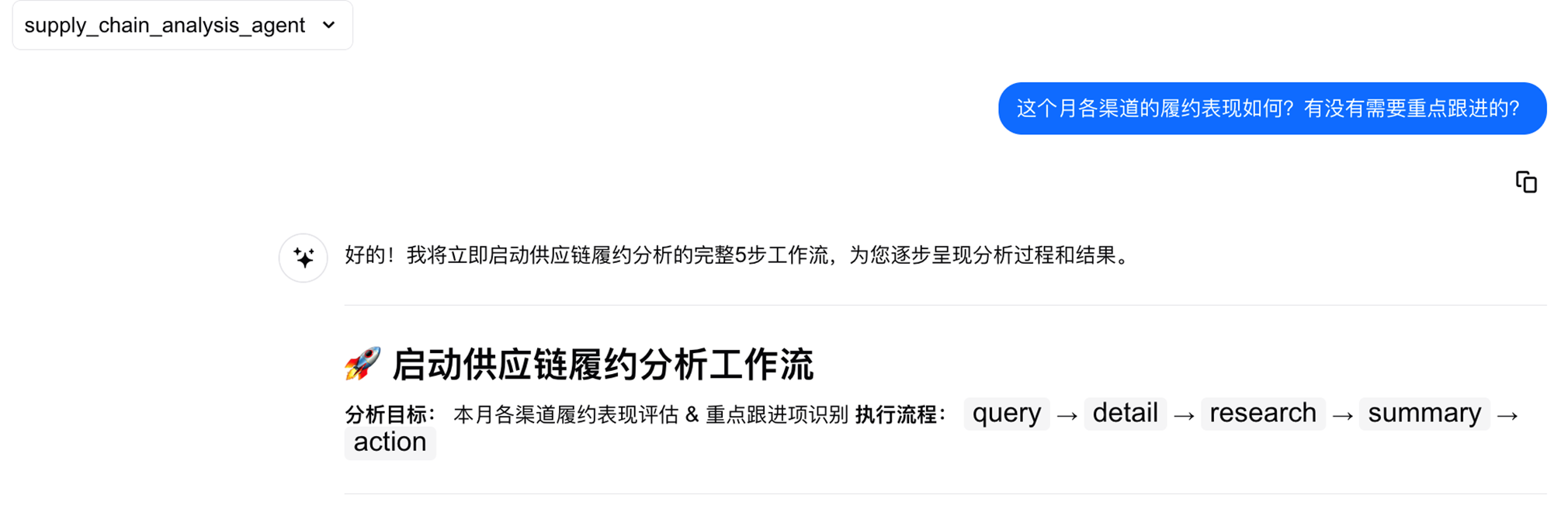
运营经理在月度回顾时提出一个问题:这个月各渠道的履约表现如何?有没有需要重点跟进的?
这是一个典型的开放式分析问题——没有指定具体指标,没有限定维度,需要系统自行判断”怎么看”和”看什么”。传统模式下,回答这个问题需要:登录各渠道系统导出数据 → Excel 合并清洗 → 手动计算指标 → 逐个渠道对比 → 撰写分析报告,整个过程通常需要半天到一天。
以下是 Multi-Agent 系统的处理过程。整体分析链路如下:

[图3] |
[图4] |
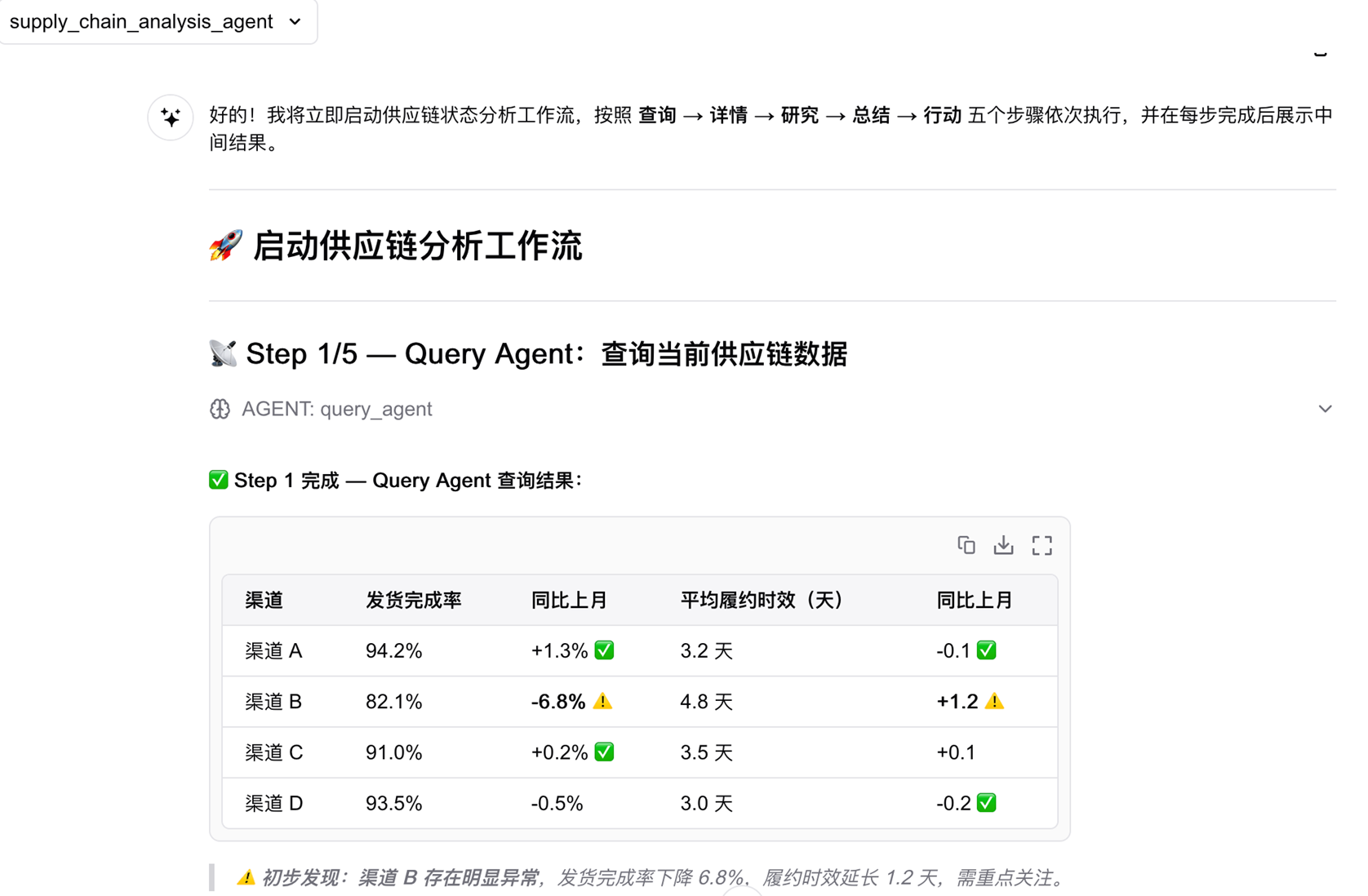
第一步:Supervisor 理解意图,调用 Query Agent 查询基础数据
Query Agent 自动将”履约表现”映射为语义层中定义的核心指标(发货完成率、平均履约时效),按渠道维度查询本月截至当前的数据,并与上月同期对比。Supervisor 识别到渠道 B 的发货完成率较上月同期下降超过 5%,判定为异常,自动进入下钻分析。
[图5] |
第二步:调用 Detail Agent 做多维度下钻
按品类和时间维度拆解渠道 B 的数据,定位异常集中在哪里:
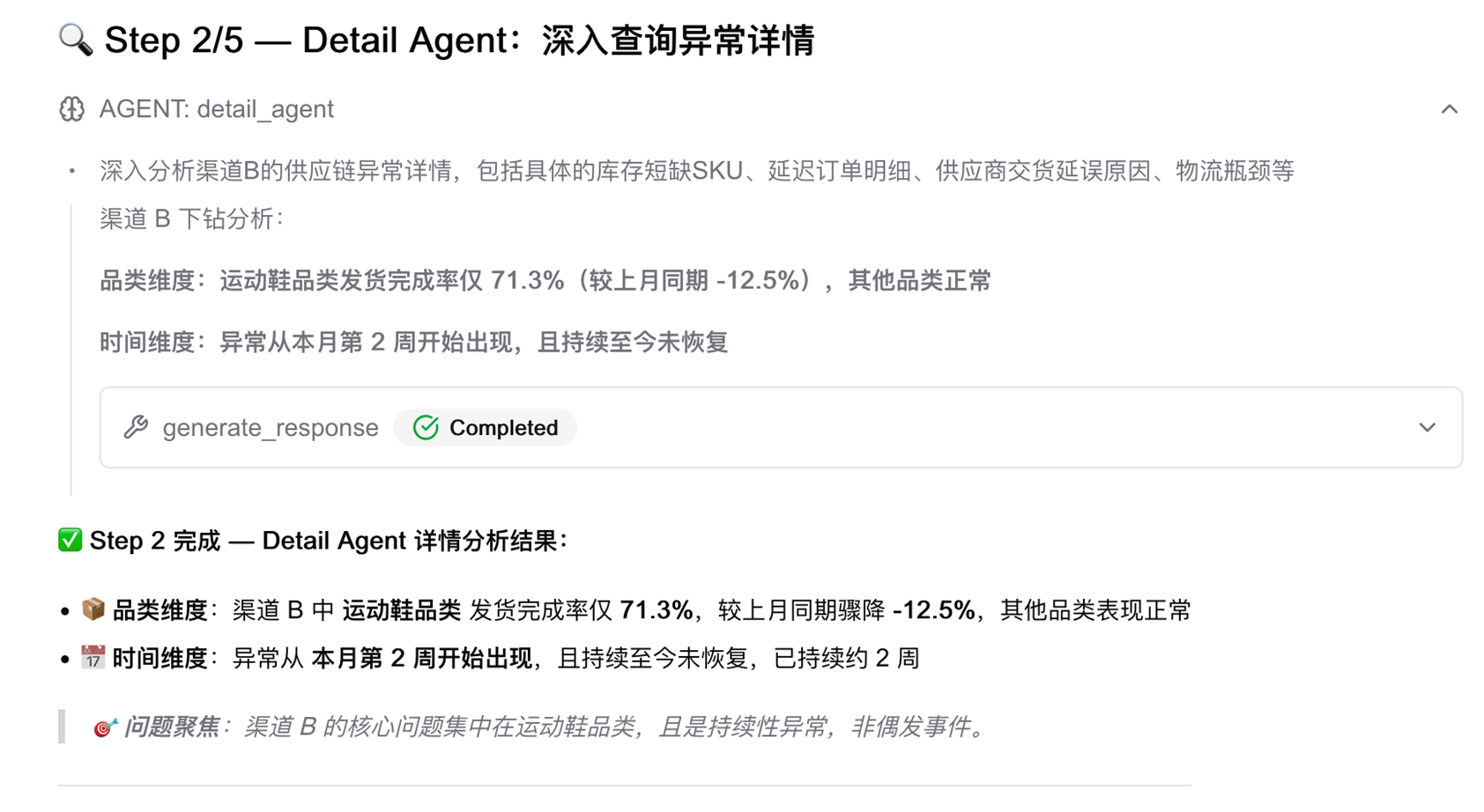
[图6] |
第三步:调用 Research Agent 做根因分析
从多个方向排查运动鞋品类在渠道 B 的履约异常原因:

[图7] |
第四步:调用 Summary Agent 生成分析总结

[图8] |
第五步:调用 Action Agent 执行行动
根据分析结果, Action Agent 自动执行两项行动:
行动 1:自动发送通知
行动 2:生成订单释放申请摘要(供审批流程使用)
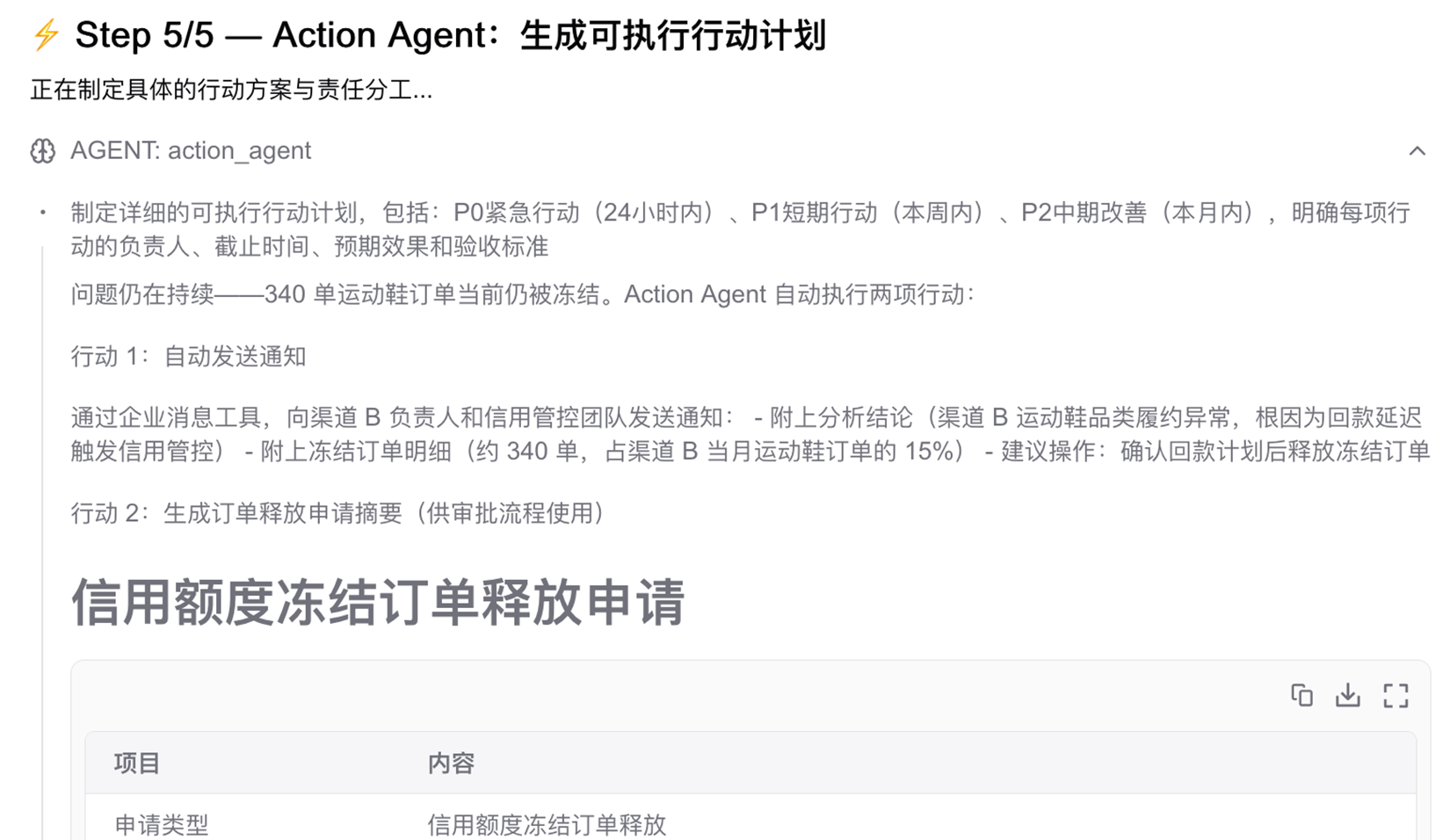
[图9] |
Agent 不只是查了数据——它完成了一个完整的分析与行动链路。回看前文提到的三层瓶颈:Query Agent 和 Detail Agent 通过语义层和 MCP 自动将自然语言转为精准的数据查询,消除了查询壁垒;Research Agent 和 Summary Agent 将原本依赖经验的归因分析变成了可复现的推理链路,填补了洞察缺位;Action Agent 直接发出通知并生成执行材料,将洞察转化为行动——不是”准备好了等人来看”,而是主动推送到需要行动的人手中。
五、扩展路径
当前系统覆盖了决策链路的核心环节——数据感知、分析洞察、执行行动。以下是进一步的演进方向:
- 知识库增强(RAG): 当前业务知识通过语义层注入 System Prompt,适合规则明确、量可控的场景。但随着覆盖面扩大,行业知识(品类季节性规律)、历史案例(过去类似异常的处理方式)、行动模板库(不同异常类型对应的处理流程)会超出 Prompt 容量。可以考虑引入知识库作为 Agent 的检索工具,不改变现有架构,仅需增加一个 MCP 数据源。
- 主动预警(Alerting Agent): 不等用户提问,Agent 主动监控关键指标,异常时推送告警并附上初步分析。这将系统从”被动应答”升级为”主动监控”。
- 进一步增强行动能力(Action Agent):让 Agent 对接下游业务系统(ERP 审批流、工单系统),进一步闭合”行动脱节”。
- 跨职能 Agent 联动: 供应链问题往往牵扯财务、销售、物流。未来可以让供应链 Agent 与其他业务域的 Agent 协作,生成跨部门的联合应对方案。
六、总结
供应链的竞争,本质上是决策速度和决策质量的竞争。”数据驱动”不是把数据集中到一个 Dashboard 就完成了, 而是从数据感知、到分析洞察、到行动执行,整条决策链路都需要被打通。AgenticAI时代的核心命题,是让数据自动流向决策、流向行动。让每一个运营决策都有数据支撑、有推理链路、有行动方案, 这才是从 data-informed 到 data-driven 的真正跨越。
➡️ 下一步行动:
相关产品:
- Amazon DynamoDB — 无服务器分布式 NoSQL 数据库
- AWS Lambda — 无需服务器即可运行代码
- Amazon Cognito — 安全注册和登录
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
相关文章:
- 用 Kiro构建 AI:基于 AWS 基础设施快速构建企业级 Agentic AI 平台
- Agentic AI基础设施实践经验系列(九):Context Engineering 上下文工程
- 【Agentic AI for Data系列】开发新范式:AI驱动的数据革命(先导篇)
- 【Agentic AI for Data系列】Kiro实战:DuckDB vs Spark技术选型全流程
- 企业级Agentic AI架构设计
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
