亚马逊AWS官方博客
存之有序,治之有矩——Agent 记忆系统的工程实践与演进
摘要:本文是”解决 Agentic AI 应用 Token 爆炸问题”系列的第三篇,系统讨论 Agent 记忆系统在生产环境的工程税:从写入纪律、Prompt Cache 冲突、跨模型容量、Embedding 迁移到 Agent 自产 Skill 治理,以及 S3 Files / S3 Vectors / AgentCore Memory 在亚马逊云科技上的落地路径。
目录
1. 引言
在 Agent 工程化的路上,记忆系统是不可或缺的一部分。本文是Agent Harness之Data for AI系列第三篇,承接开篇《取之有度,用之有节——从 Harness 视角破解 Agent 应用 Token 爆炸难题》,主要探讨Agent的记忆系统。
在进入本篇议题之前,有必要提及此前团队已发布的三篇记忆相关博客。它们系统地讨论了”记忆装什么、装在哪、怎么选存储”——从 Mem0 与亚马逊云科技的集成方案、向量存储选型,到记忆产生/策略/存储/检索四维度的最佳实践:
- 《相得益彰:Mem0 记忆框架与亚马逊云科技的企业级 AI 实践》(2025-09)
- 《Agentic AI 基础设施实践经验系列(三):Agent 记忆模块的最佳实践》(2025-09)
- 《相得益彰 — 亚马逊云科技向量存储选型推荐》(2025-11)
但当客户把这些架构真正落到生产环境后,反馈很快指向另一类问题:
- 模型替换后,历史向量要不要全部重建?
- 记忆每次写入都会让 Prompt Cache 失效,缓存和记忆天然冲突吗?
- Agent 开始自己写 Skill——这些自产内容谁来负责?
- 文件式记忆要上云,能不能免运维?
这些问题的共同特征是——存储选型已经选好了,但记忆系统依然在”失控”,主要涉及记忆系统的纪律、迁移、一致性、质量评估等数据工程命题。因此,本篇不再重述此前三篇已讲清的全景,而是聚焦记忆实现的工程议题——我们称其为记忆系统的”工程税”:每一次记忆写入、迁移、切换、淘汰时被隐性征收的成本。
2. 2026 的新变量
此前三篇记忆相关博客集中发布于 2025 年 9-11 月。短短半年内,记忆工程的落地环境发生了几个关键变化:
开源 Coding Agent 崛起
- OpenClaw(2025-11 发布)以”Markdown 文件 + SQLite索引 + Dreaming 记忆整理”为代表,推动文件式记忆成为一类实际工程选项
- Hermes(2025-07 发布,2026 初被广泛采用)率先把”Agent 自主编写 Skill”从概念变成生产机制,并在此基础上迭代出后台生命周期治理(Curator)
亚马逊云科技基础设施扩展
- Amazon S3 Vectors(2025-12 GA)——专为向量数据设计的 S3 bucket 类型,面向大规模冷向量场景,相比传统向量数据库可显著降低存储成本
- Amazon S3 Files(2026-04推出)—— 让 S3 桶像文件系统一样被 EC2、容器、Lambda直接挂载读写(NFS v4.1+),多计算资源可并发共享同一份数据,无需复制。
- Amazon Bedrock Prompt Caching 进入稳定可用阶段——带来”记忆写入如何与 Cache 前缀稳定性共存”这一全新工程议题
模型层
Amazon Bedrock 托管的模型生态持续扩大——除了 Anthropic Claude 4.x、Amazon Nova、Meta Llama、Mistral 外,DeepSeek、Qwen3、MiniMax、智谱、Moonshot 等中国模型家族也已作为托管 Serverless 模型接入。不同模型使用不同分词器,记忆容量上限用字符还是 Token 衡量从设计偏好变成了实际工程问题。
这些变量叠加的结果是:2026 年的 Agent 记忆工程,不是 2025 年答案的重复,而是新地形上的新铺路。
3. Part 1. 记忆系统的五个工程考量
生产环境中,有五个工程考量往往被低估–单独看每一项都不致命,但叠加起来,足以让一个架构设计合理的记忆系统在运行半年后变得难以维护。
考量一:写入纪律与失效机制
哪些内容值得永久化?过时的记忆怎么识别?”什么是重要的记忆”这个判断本身缺乏通用评估方法。更棘手的是失效场景——有三类尤其隐蔽:
- 低频但重要(如用户关键背景、过敏信息),容易被访问频率淘汰误伤
- 时间新但语义旧(用户复述三年前状态的记录),时间戳新不等于内容新
- 并存而非冲突(三年前保守 vs 今年激进),两条记忆都真实且未被否定,LLM 判官不会判定为矛盾
考量二:写入与 Prompt Cache 的冲突
Bedrock Prompt Caching 要求 System Prompt 前缀逐字节匹配。记忆系统每写一次都会破坏这个前提,让”启用 Cache”的成本收益归零。
考量三:跨模型的容量上限
Bedrock 托管的多个模型可能使用不同分词器。同一段中文记忆在不同模型下 Token 数可能出现倍数级差异,按 Token 设置的记忆容量上限,换模型就要重新调参。
考量四:Embedding 迁移的数据税
LLM 替换是轻量工作,Embedding provider 替换却牵动所有已有记忆的向量表示——维度可能变、语义空间一定变,历史向量必须重建,迁移期间对话不能中断。一个上线三年的 Agent 可能经历多次这样的迁移。
考量五:Agent 自产程序性记忆的治理
2026 年最显著的新变量是 Agent 开始自己编写可复用的 Skill。Skill 的质量评估、失效判断、治理者本身的审查——都是传统陈述性记忆系统不存在的新问题。
这五个考量有一个共同点——它们都属于”架构已定、运行才开始”的问题:选型阶段看不出,上线半年后才集中显形。后续章节逐一展开——每章给出业界当前的解法、适用边界、以及在亚马逊云科技上的落地路径。
4. Part 2. 记忆的写入纪律与失效机制
所有长期记忆系统都面临同一个判断题:这条新写入,值不值得留?该新增、合并,还是丢弃?
业界目前有三条路径,对应三种工程哲学。
4.1 路径一:LLM 判官
Mem0 是这一路径的代表。Mem0 v2 采用了双 LLM 架构(信息提取 LLM + 决策 LLM,后者输出 ADD / UPDATE / DELETE / NONE)。从”重要性评估”视角看,这一思路在语义层面最鲁棒——LLM 能识别”我喜欢 Python”和”我讨厌 Python”是语义相反而非语义相似,向量相似度做不到这一点。其代价是每次写入都消耗两次 LLM 调用的 Token,在高频写入场景下成本显著增长。用小模型做决策 LLM 可以缓解成本,但会在边缘情形下出现误判。这条路径的本质 tradeoff 是”准确率 × 成本”——这在任何业务里都没有一劳永逸的最优点。
值得注意的是,Mem0 于 2026-04 发布的 v3采用 Single-pass ADD-only extraction——只做 ADD,由检索层去做事实合并与冲突处理,不再走 UPDATE/DELETE 路径, 这个决定很有可能是出于成本的考量,但”用 LLM 做语义判断”的路径哲学没变。
4.2 路径二:公式打分
OpenClaw 的 Dreaming 系统是这一路径的代表。它不为每次写入付出 LLM 成本,而是把”重要性评估”放在后台周期性任务里完成——对所有候选记忆用一组确定性加权公式打分,分数低于阈值的保留在短期,高于阈值的晋升为长期记忆。
三个阶段各自的职责(基于 OpenClaw docs/concepts/dreaming.md,验证时 HEAD bd20f8e07e,对应 v2026.4.12-beta.1-7921-gbd20f8e07e,验证时间 2026-05-01):
| 阶段 | 职责 | 产出 |
| Light(筛选候选) | 从近期对话和召回记录里挑出”可能值得留下”的候选,去重 | 候选记忆清单(暂存短期) |
| REM(模式反思) | 在候选之上做模式识别,产出”强化信号”——标记哪些候选在主题上反复出现、彼此相关 | reinforcement signal,供 Deep 使用 |
| Deep(晋升长期) | 用六维公式 + 三重门槛打分,决定哪些候选真正写入 MEMORY.md | 晋升后的长期记忆 |
每次 sweep(一次完整的”扫一遍所有候选记忆”任务)按 Light → REM → Deep 顺序运行——REM 先标出”哪些候选值得 Deep 重点关照”,Deep 再基于 REM 的强化信号打分晋升。一次 sweep 跑完,本轮任务结束,直到下次 cron 触发再跑。
Deep 阶段的六维打分公式——这是公式打分思路的核心:
| 维度 | 权重 | 描述 |
| Frequency(频次) | 0.24 | 这条记忆在短期里被引用了多少次——被引用越多,越像值得保留的”常用知识” |
| Relevance(相关度) | 0.30 | 这条记忆被召回时,用户/Agent 真的”用上了”吗——每次召回后的相关性评分平均 |
| Query diversity(查询多样性) | 0.15 | 这条记忆是被多少种不同问题触发的——被同一类问题反复触发不算数,被多样问题触发才说明覆盖面广 |
| Recency(新鲜度) | 0.15 | 这条记忆最近被用过没——越久没被用,分数越低 |
| Consolidation(跨日复现) | 0.10 | 这条记忆是连续多天都被用到的吗——只在一天内集中出现可能是偶发,跨日复现才像长期有用 |
| Conceptual richness(概念密度) | 0.06 | 这条记忆包含多少有意义的概念标签——纯闲聊的标签密度低,实质性事实的标签密度高 |
光打分高还不够——Deep 阶段同时设了三重硬门槛:minScore(综合分要达标)、minRecallCount(至少被召回过 N 次)、minUniqueQueries(至少被 N 种不同查询触发过)。三重门槛同时满足才能晋升,任何一条不达标就留在短期。这种”公式打分 + 硬门槛”的双保险设计,是为了防止某一维异常值把整体分拉高导致误晋升。
优势:Deep 阶段的晋升决策完全确定性——六维公式打分 + 三重门槛判定不经过 LLM,零推理成本、完全可预测。Light 阶段的候选提取仍需 LLM 参与。此外,可选的 Dream Diary(把 Dreaming 结果写成人类可读叙事)会调用 subagent LLM 生成文本,启用时有额外 token 成本。
代价:阈值与权重的调优是黑盒,且不暴露为用户级配置。六个维度的权重(0.24 / 0.30 / 0.15 / 0.15 / 0.10 / 0.06)、Deep 的三重门槛取值,OpenClaw 官方文档明确其为 “internal implementation details, not user-facing config”——用户级配置只暴露 enabled 和 frequency(cron)两个键。这意味着如果默认参数对某业务不合适,需要通过修改源码或编写扩展插件来覆盖默认值,这是一道不低的二次开发门槛。业界对这些权重也没有通用指导,默认参数是否适用需要团队自行验证。
运行配置:默认 cron 0 3 * * *(每天凌晨 3 点)触发一次完整 sweep;OpenClaw 官方文档明确 Dreaming 默认关闭(opt-in 启用)。在可接受”默认参数先跑起来、必要时通过二次开发调参”这一工程路径的场景下,它是一个可用的公式打分参考实现。
4.3 路径三:托管策略(内置 + 可自定义)
Amazon Bedrock AgentCore Memory 采用第三种思路——把”重要性评估”抽象成可配置的策略,开发者选用或改写策略,而不是自己从零实现决策逻辑。
AgentCore Memory提供四种内置策略覆盖常见场景:
- SemanticMemoryStrategy(语义策略)——提取客观事实与知识点
- SummaryMemoryStrategy(摘要策略)——把长对话压缩成短摘要
- UserPreferenceMemoryStrategy(用户偏好策略)——提取用户偏好、风格选择
- EpisodicMemoryStrategy(情节策略)——保留完整交互经历以便复盘
开发者选一个对应场景的策略,AgentCore 在会话结束时自动提取对应类型的记忆片段。
每条策略的底层执行两步流水线:Extraction(从对话中提取)→ Consolidation(与已有记忆整合去重)。Episodic 策略额外多一步 Reflection(对经历做反思总结)。
此外,AgentCore 支持对内置策略做覆写——可覆写的环节按策略不同而异:
| 策略 | 可覆写环节 |
|---|---|
| Semantic | Extraction + Consolidation |
| UserPreference | Extraction + Consolidation |
| Summary | Consolidation |
| Episodic | Extraction + Consolidation + Reflection |
覆写的方式是追加或修改 LLM 的 system prompt 指令(输出 schema 不可改)。启用覆写后,Extraction 和 Consolidation 阶段的 LLM 调用会从你的 AWS 账号计费。
这一路径的优势是零运维、与 Bedrock 生态深度集成、以及”内置兜底 → 覆写调优 → 完全自管理”的三级渐进式定制路径。内置策略适合标准场景;覆写(built-in with overrides)适合需要调整提取/整合指令但不想自建流水线的场景;当业务需要跨策略协同或完全自定义 schema 时,可切到 self-managed strategy 完全接管。
4.4 路径四:workload-feedback adaptation
严格来说这不是与前三条并列的第四种方案——前三条都由系统设计者预判”什么重要”(LLM判官靠世界知识、公式打分靠预设权重、托管策略靠策略抽象),路径四则不预判,而是让系统从自身的历史查询分布中学到”用户关心什么”,据此决定提取和保留什么。
LinkedIn 在其生产 Hiring Assistant 上部署的 HLTM(Hierarchical Long-Term Semantic Memory,2026-04 发表)就采用了这一思路。核心机制是:系统会统计过去一段时间用户问了哪些类型的问题,然后据此调整”下次该提取和记住什么”。举个例子:如果系统发现用户 80% 的问题都是关于”候选人的技术栈”和”工作年限”,那下一轮记忆提取时就会优先抽取这两类信息(而不是等 LLM 自己猜用户关心什么)。HLTM 的消融实验显示,去掉这一机制后,记忆召回的准确率下降了约 10 个百分点。
这条路径的工程哲学优势是——让记忆内容被真实工作负载塑形,不依赖任何 Agent 框架作者的世界知识假设。代价是冷启动期间没有历史 query 可用,需要 bootstrap (如 offline 生成 seed pattern,或先积累一段 query 日志再开启)。这条路径跟前三条不是互斥关系——如果你已经在用路径一/二/三,为它加上一个”从历史 query 分布反馈”的信号源,可以减少对设计者预判的依赖。
4.5 延伸:图结构下的失效判断
上述几条路径默认记忆是扁平的条目集合,但当记忆以图结构抽象存在——实体作为节点、关系作为边、事实带时序演化——“什么值得留、什么过时”,则需要有额外的处理逻辑。
Graphiti 是图结构记忆的代表实现——用图(而非扁平列表)存储记忆。它不按’重要性评分’决定去留,而是采用双时间轴(bi-temporal)事实有效性窗口:每条事实边都带有两个时间——事实本身的有效起止时间(这条关系从何时成立、何时失效)与该事实被摄入系统的时间(provenance)。当新事实进入系统且与旧事实冲突时,Graphiti 不会删除旧事实,而是把旧事实标记为 invalidated(失效);旧事实仍留在图中,支持历史回溯查询。
Graphiti 这套设计回答”记忆过时”的方式是:
- 不删,只标记——“三年前保守投资”这条事实不会消失,会带上”2023-xx 至 2026-xx 有效”窗口;“今年激进投资”作为新事实进入后,旧事实被标记为 superseded
- 时间敏感查询——Agent 问”客户当前的投资偏好”时,查询只返回当前有效的事实;问”2023 年客户偏好什么”时,系统仍能检索到
- 保留 provenance——每条事实可追溯回它来自哪条原始数据(episode),方便审计和解释
这套”时间窗口 → 当前有效筛选”的失效哲学,跟扁平条目常用的”重要性评分 → 淘汰”是完全不同的思路。不过图结构的工程代价也不小,Mem0 v3就权衡后撤掉了图后端——v2 及更早版本支持Neo4j/ Neptune等图后端,但在 2026-04 合并的 v3 pipeline提交(a488e190)里,它转向了更轻量的实体关联方案:存记忆时自动提取实体,跨记忆建立关联,查询时对匹配到的实体相关记忆做加权排序,不再做图遍历和多跳推理。(Neptune Analytics 作为向量存储后端仍保留,只是不再承载 Cypher/图遍历角色)。
两种设计各有适用场景:用户偏好这类”当前状态快照”更适合扁平路径,而客户关系演化、医疗病历、合同修订这类”需要历史回溯”的场景更适合图谱路径。
5. Part 3. 记忆写入与 Prompt Cache 的冲突
Amazon Bedrock 的 Prompt Caching 对长 System Prompt 的成本降幅显著。以 Claude Sonnet 为例,cache hit 的 Input Token 计费为标准价的 0.1 倍,5 分钟 TTL 的 cache write 为 1.25 倍(Bedrock 与 Anthropic 官方比例一致)。但这个收益建立在一个容易被记忆系统破坏的前提上——System Prompt 前缀必须逐字节匹配。
5.1 冲突是怎么产生的
记忆内容通常作为 System Prompt 的一部分,在每轮请求开始时注入。问题在于:
- 如果记忆在对话中途被写入(用户刚说了一个新偏好)
- 而这次写入被立刻反映到下一轮的 System Prompt 里
- 那么 System Prompt 前缀就和上一轮不一致了
- Cache miss → 下一轮按 cache_write 价格重建缓存
长会话高频写入场景下,Cache 命中率可能长期低于预期。这是存储选型无法解决的工程问题——跟用 DynamoDB 还是 Aurora 无关,跟记忆什么时候被反映到 Prompt有关。
5.2 三种处理思路
业界目前有三种处理方式:
A. 接受 Cache 失效。 最简单——每次记忆变更后下一轮走 cache_write。适用于会话短、写入频率低的场景。
B. 记忆放 User Message 而非 System Prompt。 保留 System Prompt 的 Cache 命中,但牺牲记忆在 System Prompt 层次的约束力——模型对 System Prompt 指令的服从度通常高于 User Message。
C. 冻结快照(frozen snapshot)。 会话启动时将磁盘记忆加载为一个不可变快照,会话内所有写入只落盘、不修改当前会话的 System Prompt;下次会话启动时才重新加载。这样本会话的 Cache 前缀稳定,记忆写入对当前会话的 Cache 命中率无影响。
思路 C 在开源 Agent 框架中的一个代表实现是 Hermes Agent。其 MemoryStore 类(位于 tools/memory_tool.py)在 load_from_disk() 时将格式化后的记忆写入 _system_prompt_snapshot,并在会话期间保持不变;add / replace / remove 操作立即写入 MEMORY.md / USER.md,但 format_for_system_prompt() 返回的始终是快照而非 live 状态( Hermes HEAD = e5dad4ac5, 核对时间 2026-05-01)。
5.3 在 Bedrock 上落地思路 C
在 Bedrock Converse API 上实现思路 C 的关键是合理放置 cachePoint——让记忆快照落在 cache 边界之前,让动态内容落在 cache 边界之后。整体结构与 Cache 命中效果如下图所示:
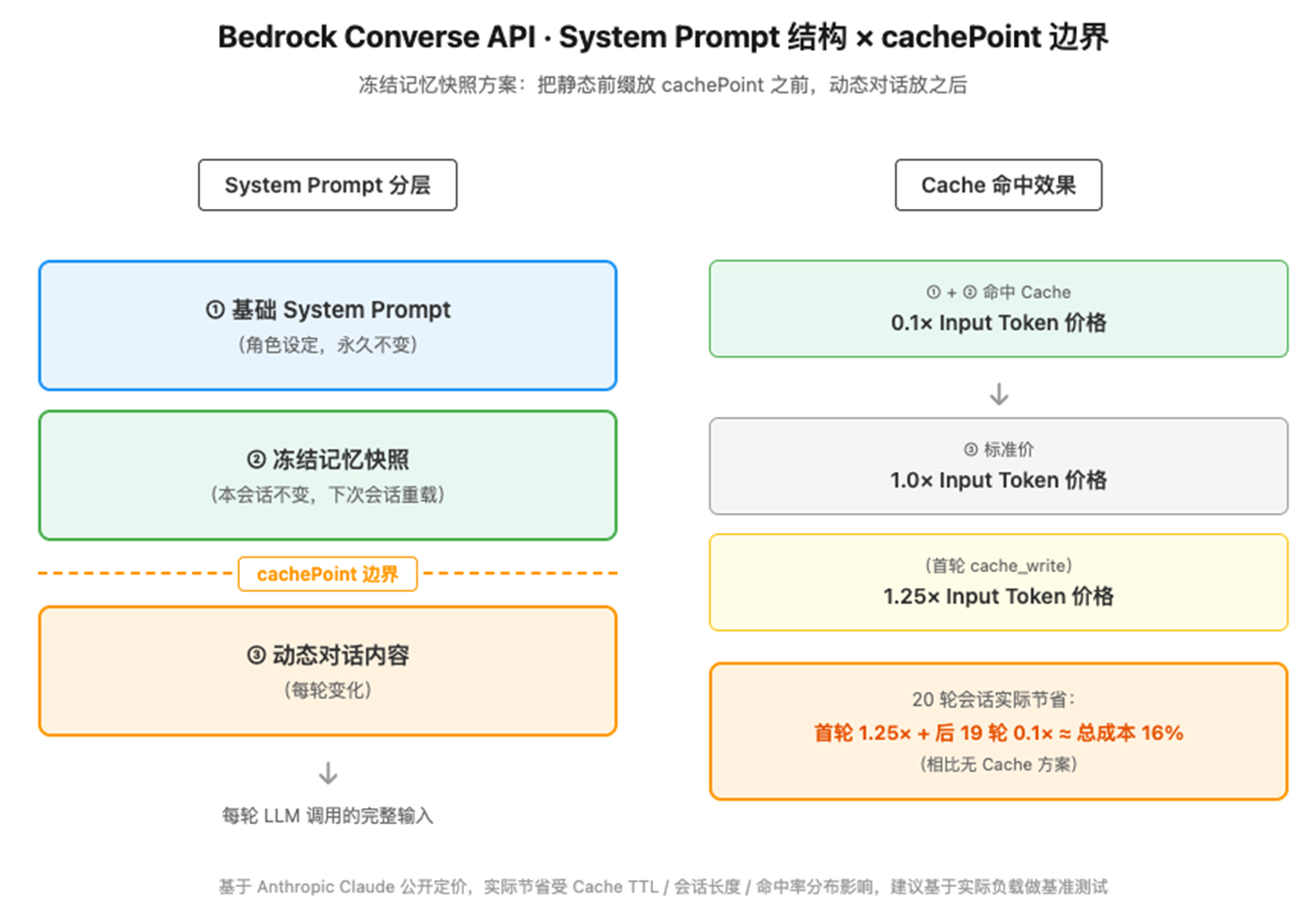
[图1 Bedrock Converse API · System Prompt 结构 × cachePoint 边界] |
图1左侧展示 System Prompt 三层分层(基础 System Prompt → 冻结记忆快照 → cachePoint 边界 → 动态对话内容);右侧展示三类 Cache 命中效果对应的 Input Token 价格档位。右下方给出20 轮会话的成本算例。
上图算例的前提假设是:System Prompt 中记忆段约 3KB、20 轮会话、以 Claude Sonnet Input Token 定价为参照、无 Cache 策略作为基线。在思路 C 下,记忆段的 Input Token 成本可降至约 16%。实际节省取决于 Cache TTL、会话长度、命中率分布等因素,且 Anthropic 对 prompt caching 有最小前缀长度要求,落地前建议基于实际负载做基准测试。
以下脚本提供了在EC2上实现的示例——前 3 轮冻结快照保持 Cache 命中,第 4 轮模拟”写入立刻生效”打破 Cache:
输出:
第 1 轮:system prompt + memory(约 4035 tokens)首次写入 cache。第 2-3 轮:system 不变,4035 tokens 全部走 cache hit(0.1x 价格),只有新增的 user/assistant messages 按标准价计费。第 4 轮:修改了 system[1][“text”](追加一条记忆),前缀字节变化,cache 失效,重新走 cacheWrite。这组数据验证了冻结快照的核心价值——只要 system 不变,Cache 就持续命中;一旦动了,立刻失效。
注:Prompt Cache 最低触发阈值为 1024 tokens(Claude 系列),低于此阈值 cacheWrite 不会生效。Cache TTL 默认为 5 分钟,超时后下次调用会重新 cacheWrite。
冻结快照不是免费的。它的代价是——本会话内新写入的记忆对当前会话不可见。如果用户在对话早期说了一个关键事实、期望 Agent 在后续几轮立即用上,冻结快照做不到;要么等下次会话,要么退回到思路 A/B。这背后是一个可迁移的设计原则——“写入”和”生效”不是同一件事,也不必同步发生。
6. Part 4. 跨模型的容量上限:字符vs. Token
Bedrock 托管多家模型,它们使用不同的分词器。尤其在中文场景下差异显著:同一段中文在不同模型下 Token 数可能出现倍数级差异——英文优化的分词器(如早期 Llama)对中文通常更耗 Token,中文原生训练的分词器(如 Qwen、DeepSeek)则相反。
这一事实对记忆系统的”容量上限”设计提出了一个实际问题:
如果用 Token 作为记忆文件的硬上限,换模型就要重新调参。 配置”MEMORY.md 不超过 2000 Token”,切换到另一个模型后这个阈值可能偏紧或偏松。在多模型生态里,按 Token 设限意味着每次模型切换都要重新校准记忆容量参数。
字符级上限是一种更稳健的设计选择。 Hermes Agent 对此的做法是:MEMORY.md 默认 2200 字符、USER.md 默认 1375 字符 (Hermes HEAD = e5dad4ac5,核对时间 2026-05-01,见 tools/memory_tool.py)—— 字符级约束跨模型无感切换。同一套记忆配置用于任何分词器的模型,不需要重新调参。
这个设计带来的取舍:字符数和 Token 数不是线性关系——2200 个英文字符约 550 Token,同样字符数的中文在 Claude 分词器下约 2200 – 3300 Token(中文原生分词器如 Qwen/DeepSeek 会更低),代码段落又不同。所以”字符上限”不是一个能精确对应 Token 成本的控制手段。但在多模型生态下,”跨模型稳定”的价值通常超过”跨语言精确”的损失——单模型场景下,你可以按 Token精细调参;多模型场景下,你要么接受每次换模型重调,要么接受字符上限这个稍粗但稳定的抽象。实操建议:多模型生态下用字符上限做硬约束兜底,单模型生产环境再按目标模型的分词器叠一层 Token 级监控告警,超阈值告警但不阻断写入。
补充一点:上限机制本身能带来强制取舍——超限时直接拒写,并返回当前用量提示模型调用 replace 或 remove,避免记忆无限膨胀。这跟”字符 vs Token”的选择是正交的两件事。
7. Part 5. Embedding 迁移:记忆工程的数据税
2026 年 Agent 开发者可能需要频繁面对模型替换——Claude 3.x 升到 Claude 4、从 OpenAI 切到 Bedrock,或切换到新推出的 DeepSeek / Qwen 等托管模型。
LLM 替换本身是轻量工作——修改配置、换 API endpoint 就够了,无需动已有数据。但如果替换的是 embedding provider(例如 Titan v1 → v2、团队自建的 BGE-m3 升级到更大模型、或从 OpenAI embedding 切到 Bedrock Titan)——则是完全不同量级的工作,因为它涉及已有记忆的向量表示。
7.1 问题规模
不同 embedding provider 的向量之间可能并不兼容:
| Provider | 维度 |
| Amazon Bedrock Titan Embeddings v2 | 1024 / 512 / 256(可选) |
| OpenAI text-embedding-3-large | 3072 / 1536(可选) |
| Cohere Embed v3 | 1024 |
| BGE-m3 | 1024 |
| Google Gemini gemini-embedding-2 | 灵活 128-3072,推荐 768 / 1536 / 3072(默认 3072) |
维度不一致是最表面的问题——就算维度相同(比如 Titan v2 1024 维和 BGE-m3 1024 维),它们处在不同的语义空间,cosine 相似度在两个空间之间不可迁移。“我喜欢 Python”在 Titan 空间中最近邻的向量,和在 BGE-m3 空间中最近邻的向量,可能完全是两条记忆。
这意味着切换 embedding 时,历史所有向量需要用新 provider 重算、迁移期间新旧向量不能混用、而对话不能中断——Agent 仍在继续服务,记忆仍在被查询和写入。这就是”数据税”——不是选错了存储、也不是架构设计不良,而是 embedding 生态本身的不兼容导致的不可避免的工程代价。
7.2 四阶段迁移方法论
一条在生产环境验证过的迁移路径是双写 + 异步回填 + 读路径切换 + 归档:
7.2.1 阶段 1:双写(Dual Write)
新写入的记忆同时用两个 provider 生成向量,分别存入新老向量表。读路径仍走老表——新 provider 出问题可以随时回退,老向量仍是读路径唯一依赖。
# 双写示例(伪代码 + 真实 Titan 调用)
7.2.2 阶段 2:异步回填(Backfill)
后台进程批量读取老表中尚无新向量的历史记忆,用新 provider 计算后写入新表。这是耗时最长、成本最高的阶段——规模达到百万级记忆时,回填可能持续数天并消耗大量 Bedrock Embedding 调用配额。
回填阶段最容易踩的三个坑:
- 配额打满——需要在回填前评估 Bedrock 的 RPM(Requests Per Minute)限额,必要时申请配额提升
- 批量失败的重试边界——单条失败不应阻塞整批,但整批失败应该暂停
- 中途配置漂移——如果回填脚本和新写入路径用了不同的 embedding 配置(维度不一致、normalize 设置不同),数据会分裂成两套互不兼容的向量
7.2.3 阶段 3:读路径切换
当新表的覆盖率达到一个安全阈值(例如 99%+)后,读路径切到新表。此时老表仍在更新(双写继续),一旦新表出问题可以回退。剩下的 1% 有三种处理策略——读 miss 时 fallback 到老表(用老 provider 重新 encode query)、miss 时同步触发单条回填、或在切换前用额外配额把覆盖率推到100%。选哪种取决于业务对”老数据查不到”的容忍度。
# 读路径切换:当新表覆盖率 >= 99% 时切换
7.2.4 阶段 4:归档老向量
观察期(通常 1-2 周)之后,停止双写,老向量转入 S3 归档,不删除——因为未来还可能需要回退,或对历史数据做新的实验性检索。
# 停止双写,归档老向量
# 1. 从老表导出为文件(格式取决于 vector store)
# 2. 上传到 S3 归档层
上面的方法针对向量库。如果记忆存储在图数据库中,entity 节点的 embedding 迁移会额外涉及实体消解结果可能变化的问题——老embedding 下被判为”同一实体”的两个节点,在新 embedding下可能被判为”不同”,反之亦然。四阶段方法需要追加”消解不变性验证”步骤。
Embedding 迁移揭示了记忆系统的一个根本特性——向量表示会随基础模型演化而需要刷新。因此迁移不是偶发事件,而是工具链演化的必然产物。把迁移从”一次性灾难”变成”常规能力”,是记忆系统长期运行的必要条件——这也是双写 + 回填 + 切换 + 归档值得当成方法论沉淀下来的原因。
8. Part 6. Agent 自产程序性记忆的治理
Agent 世界里”记忆”这个词实际上有两个层次——陈述性记忆回答”我记得什么事实”(前面四章聚焦的方向:对话蒸馏、重要性评估、Prompt Cache 冲突、embedding迁移);程序性记忆回答”我记得怎么做”。后者在心理学分类里本就是记忆的子类之一——就像骑车、打字这类”身体记住怎么做”的经验——跟”记得用户喜欢Python”这类陈述性事实属于同一记忆家族的不同成员。
Agent 里的 Skill 正是程序性记忆的数字化对应:它存的不是事实,而是”遇到某类任务怎么应对”的经验——一个格式化的 SKILL.md 文件,里面写着”做 X 类任务时按顺序执行 A / B / C 步骤、避开 D 陷阱、必要时调用 E 工具”。
8.1 新范式:Agent 自己写 Skill
前面四章讨论的记忆系统有一个共同特征——记忆内容来源于人与 Agent 的对话,Agent 是记录者和使用者,创作者仍然是用户或开发者。程序性记忆的传统答案也类似:开发者编写Skill 手册,或从 Agent 日志里人工筛选有效模式写成 SKILL.md。这种”人工策展”模式适合小规模、标准化场景,但不适合每个 Agent 都有个性化工作流的生产环境。
Hermes Agent 在 2026 年给出了一个不同的解法——让 Agent 自己写 Skill。Hermes 的 skill_manage 工具(位于 tools/skill_manager_tool.py,Hermes HEAD = e5dad4ac5,核对时间 2026-05-01)允许 Agent 在对话过程中直接 create / edit / delete SKILL.md,把成功的工作流蒸馏成下次可复用的 Skill。
8.2 治理挑战:三条可迁移的治理原则
“让Agent能写”只是第一步。真正的挑战是Agent自产的内容如何作为长期可维护资产被治理。Hermes 在 2026 年 4 月引入了 Curator 模块来解决这个问题。它跟前面讨论的 OpenClaw Dreaming 共享同一套工程哲学:写入与治理分离、后台化决策、动作可逆——只是操作对象从陈述性事实换成了程序性 Skill。OpenClaw Dreaming 对候选事实用六维公式打分决定是否晋升长期记忆,Hermes Curator 对 Agent 自产的 Skill 用三状态机决定是否 archive。 从Hermes Curator的设计可以提炼出三条可迁移的原则:
- 写入与治理分离——Agent 即时写入 Skill,但质量判断不在写入时做,而是由独立的后台机制定期完成。
- Provenance 作为一等公民——系统区分“谁写的”:Curator 只治理 Agent 自产的 Skill,不碰人类策展的或社区来源的。
- 治理动作可逆 + 可审查——从不自动删除,只 archive(可恢复);每轮治理留审计记录。
具体到 Hermes 的实现:Curator 是一个独立的 auxiliary-model agent(与主会话模型隔离,不干扰 Prompt Cache),默认 7 天一轮,按 active → stale → archived 三状态机管理,每轮产出 run.json + REPORT.md 审计报告。
这三条原则共同传达一个设计约束:Agent自产内容是“可治理但不可直接销毁的”。因为“LLM 写 + LLM 治理”的闭环里两端都可能犯错, archive only(而非delete) 是对这种不确定性的工程兜底。
8.3 待解决的工程问题
Agent 自产记忆范式还留下几个未解决的工程问题:
- 使用频次作为质量信号的局限性——.usage.json 追踪调用次数,但”用得多”不等于”用得对”:一个被 Agent 频繁误用的 Skill 反而会因高频次被豁免淘汰。
- 治理 Agent 自身的质量评估——Curator 本身是一个 LLM Agent,它的治理判断需要被评估。但目前尚无广泛认可的”治理 agent 质量评估”方法论。
这两条是 Agent 自产记忆范式本身的开放问题,也是这一方向下一阶段的演化重点。
9. Part 7. Agent 记忆的新基础设施:S3 Files 与 S3 Vectors
前面五章讨论的都是工程层面的通用议题——重要性评估、Prompt Cache 冲突、跨模型一致性、Embedding 迁移、Agent 自产 Skill 的治理。工程问题最终要落到具体基础设施。近半年亚马逊云科技生态的两项更新——S3 Vectors(2025-12-02 GA)与 S3 Files(2026-04 推出)——给 Agent 记忆系统增加了一个选项:陈述性层(对话、Skill、索引文件)和语义层(向量 embedding)得以同时选择 S3 作为持久后端。
9.1 文件式记忆上云的动机与既有选项
OpenClaw、Hermes、Claude Code 等 Coding Agent 框架默认采用 Markdown 文件 + 本地索引的记忆实现——人类可读、可手工编辑、Git 可版本化、跟文件系统工具链天然兼容。这种本地实现适合个人开发者,但在团队或生产环境下会遇到三个问题:
- 多实例无法共享记忆——同一用户在不同机器或容器里跑同一个 Agent,记忆各走各的,无法汇总
- 单机故障即状态丢失——EC2 实例挂掉、容器重启、磁盘损坏都会带走记忆
- 没有统一的版本控制和审计——Git 可以版本化但依赖用户主动提交,不是记忆系统自动的属性
要解决这些问题,自然的方向是把记忆文件从本地挪到云端持久层。此前两条主要路径各有短板:
- Mountpoint for S3(mount-s3):FUSE 挂载把 S3 bucket 映射为本地路径,成本低但性能受限于协议转换,多客户端并发一致性弱
- Amazon EFS / FSx for Lustre:性能好但运维成本高——需要理解文件系统配置、性能层调优、跨区域复制策略
9.2 S3 Files:NFS 文件系统接口 + 数据落在 S3
S3 Files 于 2026-04-07 推出,通过标准 NFS v4.1+ 文件接口让 S3 bucket 直接以文件系统挂载形式被使用——底层数据仍是 S3 对象,不搬家、也不在外挂文件系统里复制一份。关键能力:
- NFS v4.1+ 完整操作——create / read / update / delete 全支持,文件应用无需改代码,挂载即用
- 活跃数据个位数毫秒延迟——足以支撑交互式工作负载
- NFS close-to-open 一致性——恰好匹配文件式 Agent 记忆的使用语义(每轮对话开始时加载 MEMORY.md,一轮结束后写入,下轮再读)
- 计算资源可就地挂载——EC2 / Lambda / ECS / EKS / Fargate / Batch
- 持久层是 S3——可利用 S3 版本控制、跨区域复制、生命周期归档等现有能力
- 按实际使用计费——存储量 + 小文件读 + 全部写操作,数据只存一份,省去传统双栈方案的搬运和重复存储成本
对文件式 Agent 记忆的工程意义:OpenClaw / Hermes / Claude Code 无需修改一行代码,将记忆目录指向 S3 Files 挂载点即可获得企业级持久性与并发能力。在 EC2上的实际迁移只需三步:
关键在第三步——符号链接让框架继续读写原路径,实际数据落在 S3 Files 上。框架对此完全无感,不需要修改任何配置或代码。
9.3 S3 Vectors:成本、规模、持久性三位一体
S3 Vectors 是专为向量数据设计的 S3 bucket 类型。它的基础设施价值来自三条彼此放大的能力:
- 成本:S3 Vectors 按存储量 + 写入 + 查询付费——不用就不付钱(no idle cost)。相比需要常开集群的传统向量存储方案,对”向量量大、查询频率低”的记忆场景,总成本可降低最高 90%。
- 规模:单 index 最多 20 亿向量、单 bucket 最多 10,000 个 index。传统向量库到几亿条就要开始考虑分片、扩容这些分布式运维,S3 Vectors 在这个量级上是自然扩展——规模伸缩的复杂度被下移到了基础设施层。
- 持久性:底层是 S3 对象存储,继承11 个 9 持久性 + 跨 AZ自动复制,不再是”需要工程团队单独设计的问题”。
其他关键属性:原生与 Amazon Bedrock Knowledge Bases 集成(RAG 场景零胶水代码)、per-index IAM policy(访问权限控制在基础设施层而非应用层)、查询延迟数百毫秒级别(不适合实时热路径)。
Agent 记忆场景下的典型适用:
- 大规模 / 合规长保的持久化主存——记忆总量跨越十亿级、或监管要求永久保留但 95% 数据极少被查询时,三条价值同时兑现。这里 S3 Vectors是主存而非冷层——数据从写入那一刻起就不会搬家
- B2B SaaS 的多租户记忆主存——per-index IAM 让租户隔离从应用层承诺升级为基础设施契约。典型场景:法律 AI 助手每律所一个 index、医疗 AI Scribe 每医院一个index。S3 Vectors 的 per-index 计费 + IAM policy 组合,让多租户隔离可以轻量地做到基础设施层——不需要每租户独立集群,也不依赖应用层 filter。
不适合的四类场景:小规模内部工具(规模不够,pgvector 更简单)、实时低延迟路径(延迟不够)、持续高 QPS(pay-per-query 会累积成显著成本)、C 端消费级百万用户(10k index/bucket 上限不够,且用户间无合规隔离硬需求)。
社区已有将 S3 Vectors 作为 OpenClaw 记忆后端的参考实现, 通过插件形式提供 auto-recall / auto-capture 能力,配合 Bedrock Titan Embeddings V2 实现语义召回。数据留在用户自己的 AWS 账户,Serverless 零运维。基础设施只需两步 CLI:
# 创建向量索引(1024维,cosine距离)
9.4 三层基础设施:陈述性 + 语义 + 情景
前面两节讨论了 S3 Files(陈述性层)和 S3 Vectors(语义层)。再加上 Neptune Analytics 这类图数据库承担的情景层,Agent 记忆系统在亚马逊云科技上呈现出清晰的三层分工:
| 层次 | 承载内容 | 亚马逊云科技服务 | 匹配的 Agent 框架 |
| 陈述性层 | 对话、Skill、索引文件、用户偏好 | S3 Files | OpenClaw / Hermes / Claude Code |
| 语义层 | 向量 embedding、相似度检索 | Aurora pgvector / OpenSearch Serverless / S3 Vectors(三选一主力) | Mem0 |
| 情景层 | 实体关系、时序演化 | Neptune Analytics | Zep / Graphiti |
注:AWS Bedrock AgentCore Memory 是托管 Memory 服务(提供 Strategy 抽象与事件编排),不映射到单一存储层,因此不在表内列出。需要”开箱即用的 Agent 记忆系统”且接受托管服务范式时,可直接采用。
语义层主力怎么选(简化原则):
- 默认 Aurora pgvector——百万级以下、需要事务一致性、团队已有 PostgreSQL使用经验
- 规模亿级以上或需要 hybrid 检索选 OpenSearch Serverless——Neural Search 原生融合语义 + BM25
- 大规模长尾 / 多租户合规场景选 S3 Vectors
三者不是同时部署的栈——先选一个主力,另两个按需补充(例如主力 pgvector + S3 Vectors 做长尾归档)。
回到三层整体分工:陈述性层回答”记了什么”(文件最自然)、语义层回答”怎么找相似”(向量最有效)、情景层回答”事情怎么演化”(图最合适)。
但三层架构不是”Agent 记忆系统的默认配置”——它是特定规模 / 合规 / 多租户条件下才值得铺开的选择。大多数 Agent 产品的记忆规模被严重高估——单用户几年累积的抽取后记忆条目往往只在几千到几万条量级,全量放进一个 vector store 都不到 GB 级。此时只需要语义层一个主力(Aurora pgvector 或 OpenSearch Serverless),陈述性层用本地文件或 S3 Files 直接承载、情景层往往也不是必需。一上来三层齐铺、引入跨 store查询聚合和回迁逻辑,工程成本永远收不回省下的存储费用。
务实路径:先跑一个语义层主力,等真实业务指标显示”某条陈述性记忆资产需要多实例共享”或”某个场景需要实体关系多跳推理”时,再逐层补齐。每一层都应由真实业务指标触发,而非架构预设。
10. Part 8. 回到 Harness 视角
本系列第一篇将 Token 爆炸定位为 Harness 的资源管理失序——”Token爆炸不是模型问题,是管理问题”。本篇展开的六个议题,是这一总纲在数据维度的延伸——记忆既是存储问题、也是纪律问题、迁移问题、质量评估问题。
这六个议题中,有些适合交给基础设施——AgentCore Memory 托管了写入决策,S3 Vectors 托管了持久性与多租户隔离,OpenSearch Neural Search 托管了 hybrid 检索;有些则是架构设计层面的判断——Embedding 迁移的四阶段路径、跨模型的字符上限设计、Agent 自产 Skill 的治理,需要开发者根据自身场景做决策。
从 Token 视角再看这六个议题,其实大多数都在省 Token——只是省的位置不同:写入纪律 / 失效机制省”无效记忆注入 Prompt”的 Input Token;Prompt Cache 冲突省 cache_write价格差(20 轮会话记忆段成本降至约 16%);跨模型一致性省反复调参的工程时间;Embedding 迁移省停机重建的推理停摆成本;Skill 治理省过期 Skill 占用 Context 的 Token。Part 7 的新基础设施讨论不直接省 Token,但同属”工程税”的控制——省的是运维层面的重复成本。记忆系统的数据纪律没做好,下游 Token 优化都是治表。
第一篇对 Token 提出的是”取之有度,用之有节”;本篇对记忆提出的是——“存之有序,治之有矩”。存储决定记忆能装多少,数据纪律决定记忆能用多久。
11. 结语
相关产品:
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon S3 Vectors — 云原生向量存储
- Amazon EC2 — 安全且可调整大小的计算容量
- Amazon OpenSearch — 搜索和分析引擎
相关文章:
- (下篇)Solutions Memory:让 AI Agent 从成功案例中持续学习 —— 双 Memory 架构实践
- 取之有度,用之有节-从Harness视角破解Agent应用Token爆炸难题
- 从应用到 Agent:开发范式正在发生什么变化?
- 当 AI Agent 学会”忘记”:Amazon Bedrock AgentCore Memory 的记忆哲学”
- (上篇)基于 AWS Bedrock AgentCore 构建企业级航空客服智能体 —— 基于AIDLC方法从需求分析到生产部署的完整实践
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
