AWS Public Sector Blog
Resilient public safety connectivity models in AWS

For justice and public safety (JPS) agencies operating workloads on Amazon Web Services (AWS), resiliency and high availability are essential. These systems support mission-critical services such as 911 call handling, computer-aided dispatch, and emergency response coordination. Even brief disruptions can affect operations and delay critical services.
AWS enables customers to design workloads that can tolerate the loss of data centers, Availability Zones, and even entire Regions. These capabilities help maintain application availability during infrastructure-level disruptions. The AWS Public Sector Blog has previously discussed nines of availability for emergency response workloads. But highly available workloads in AWS still depend on one critical factor: connectivity to AWS.
If connectivity to AWS fails, an otherwise healthy application can become unreachable, creating the same operational impact as an application outage. For JPS agencies, workload resiliency in AWS must be matched by resilient connectivity to AWS.
This post explores connectivity patterns that can help JPS agencies build resilient network paths to AWS and align them with common public safety use cases. Because every mission has different requirements for cost, complexity, performance, and operational risk, agencies should choose a connectivity model that fits their operational needs.
Hybrid connectivity fundamentals
Traffic between AWS and on-premises sites can travel across the internet or through a dedicated fiber connection directly to AWS. When going over the internet, the connection relies on the availability of the internet service provider (ISP) and any intermediary hops, which typically offer no guaranteed service-level agreement (SLA). Internet-based connectivity can be quickly configured. Choice of connectivity method can vary based on use case. Updating arrest records in a resource management system may not require a dedicated fiber connection whereas 911 call handling will.
AWS Direct Connect, which is a dedicated connection to AWS, offers SLAs for the connection availability with uptime commitments that scale based on deployment redundancy. The architecture of a Direct Connect connection has several key concepts. An AWS Direct Connect location (point-of-presence, or PoP) is a physical facility where you can establish a cross-connect to create a network connection from your premises to AWS. Some connectivity can be established quickly, but if new circuits are required, configuring Direct Connect can take weeks or months.
Agencies must confirm that all traffic is secured, which is often accomplished using FIPS 140-3 AWS endpoints or AWS Site-to-Site VPN.
For Direct Connect traffic, in addition to FIPS endpoints or VPNs, agencies might have the option to enable MAC security (MACsec) over AWS Direct Connect, which provides encryption while maintaining extremely high throughput (near line-rate) encryption.
Standard architecture
A standard architecture is appropriate for workloads where secure connectivity and basic resiliency are important, but short periods of degraded performance during failover are acceptable. This model is often a good fit for agencies that want a straightforward and cost-effective way to improve hybrid connectivity.
This architecture combines AWS Direct Connect with a Site-to-Site VPN connection as a backup path. Direct Connect provides consistent performance, low latency, and predictable throughput, whereas the VPN over the internet offers continuity if Direct Connect becomes unavailable. If a VPN isn’t required, such as when applications use HTTPS endpoints, traffic can be sent directly over the internet instead.
This model is straightforward to implement and integrates well with AWS Transit Gateway. When paired with dynamic routing protocols such as Border Gateway Protocol (BGP), the configuration can support automated failover. Adding a VPN backup is an effective and low-cost way to introduce secure redundancy for many workloads.
Agencies should plan for the limitations of VPN connections, including lower bandwidth capacity, higher latency variability, and possible performance degradation during failover events. Even with these considerations, this model provides a practical level of resilience for workloads that are important but not considered life safety critical.
Examples of this type of workload include:
- Internal tools for police and fire departments (such as human resources (HR) systems, email, or intranet sites)
- Public websites that host noncritical information
The following diagram shows the standard connectivity architecture using a single AWS Direct Connect connection for primary traffic and a Site-to-Site VPN connection over the internet as a backup path, routed through AWS Transit Gateway.
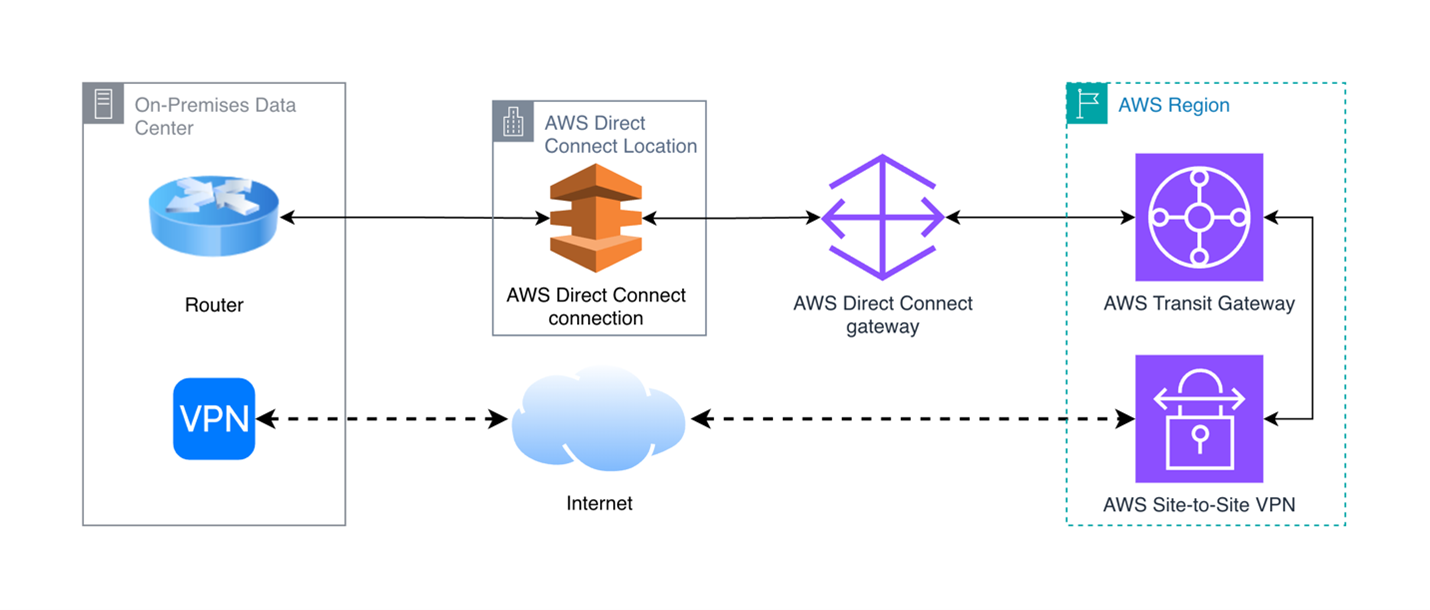
Figure 1: Standard connectivity architecture
Critical architecture
Critical architecture is best for workloads that require high availability and greater path diversity, but where a temporary outage would not directly impact life-safety operations. It reduces the risk of provider, device or PoP failure by using two Direct Connect connections in different PoPs, along with a VPN or internet-based backup.
Each Direct Connect link should terminate on a separate router, traverse a different provider network, and land in a different PoP to mitigate risks such as fiber cuts, hardware failures, or PoP outages. VPN backup (through the internet) provides an additional safety net in case of regional disruptions. If a VPN isn’t needed (for example, your application connects over HTTPS endpoints), you can send traffic directly over the internet.
This configuration allows for active-active routing and supports automatic failover. However, it requires careful planning to avoid overusing bandwidth on each link. AWS suggests limiting usage on active-active links to 50% capacity to handle potential failover scenarios without congestion.
Adding a second Direct Connect connection will increase costs because it requires purchasing a second Direct Connect port. This approach is recommended for workloads that require very high levels of availability.
Examples of this type of workload include:
- Public-facing websites that contain critical information
- Applications that are mission critical, but an outage wouldn’t impact public safety
The following diagram shows critical connectivity architecture with two AWS Direct Connect connections terminating in separate PoPs, using AWS Transit Gateway for routing and a Site-to-Site VPN over the internet as a backup path.
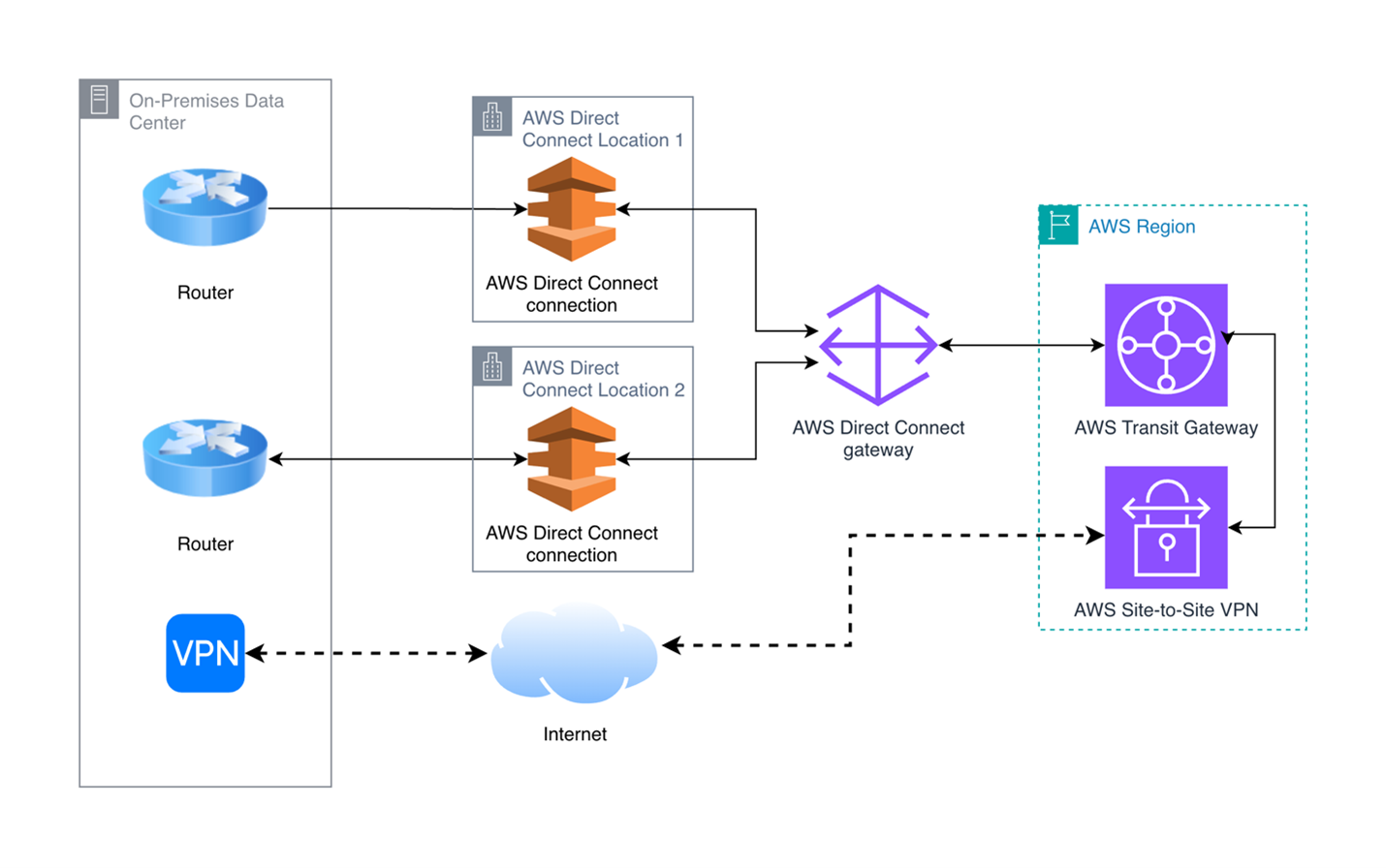 Figure 2: Critical connectivity architecture
Figure 2: Critical connectivity architecture
Public safety architecture
A public safety architecture is appropriate for workloads where connectivity loss could impair emergency communications, dispatch, or regional incident coordination. This model is designed for environments that must tolerate multiple concurrent failures by combining carrier diversity, geographic diversity, dedicated routing infrastructure and a backup internet-based connection.
This model uses four Direct Connect connections that terminate in two geographically separate PoPs. Each PoP should be supported by a different network provider. This design protects against a wide range of failure scenarios, including hardware issues, fiber cuts, provider-specific outages, and localized infrastructure disruptions. A VPN or HTTPS internet path provides an additional safeguard if all Direct Connect paths experience problems.
Each Direct Connect circuit should terminate on a separate customer router. This design helps prevent a single device failure from interrupting connectivity. The use of two independent network providers adds carrier diversity, which reduces the risk of outages caused by a single connectivity provider’s network. Geographic diversity across PoPs helps protect against natural disasters, regional events, and infrastructure failures that affect only one location.
This architecture supports active routing across all four Direct Connect links with automatic failover. Agencies should limit utilization on each link to maintain sufficient capacity for traffic redistribution if one or more circuits fail. As with the critical tier, AWS recommends keeping utilization on each active link below half of the available bandwidth to prevent congestion during failover events.
The public safety architecture involves higher cost and greater operational complexity due to multiple carrier relationships and additional network hardware. This level of investment is appropriate for agencies that support large-scale emergency communication environments, including regional 911 centers and statewide or multi-jurisdictional emergency coordination systems.
Examples of this type of workload include:
- Public safety answering point (PSAP) infrastructure
- Computer-aided dispatch systems
- Command-and-control platforms used for natural disasters or active shooter events
- Public mass notification systems and Wireless Emergency Alerts (WEAs)
The following diagram shows high-availability public safety connectivity architecture using four AWS Direct Connect circuits across two geographically diverse PoPs, with VPN or internet connectivity as a backup path.
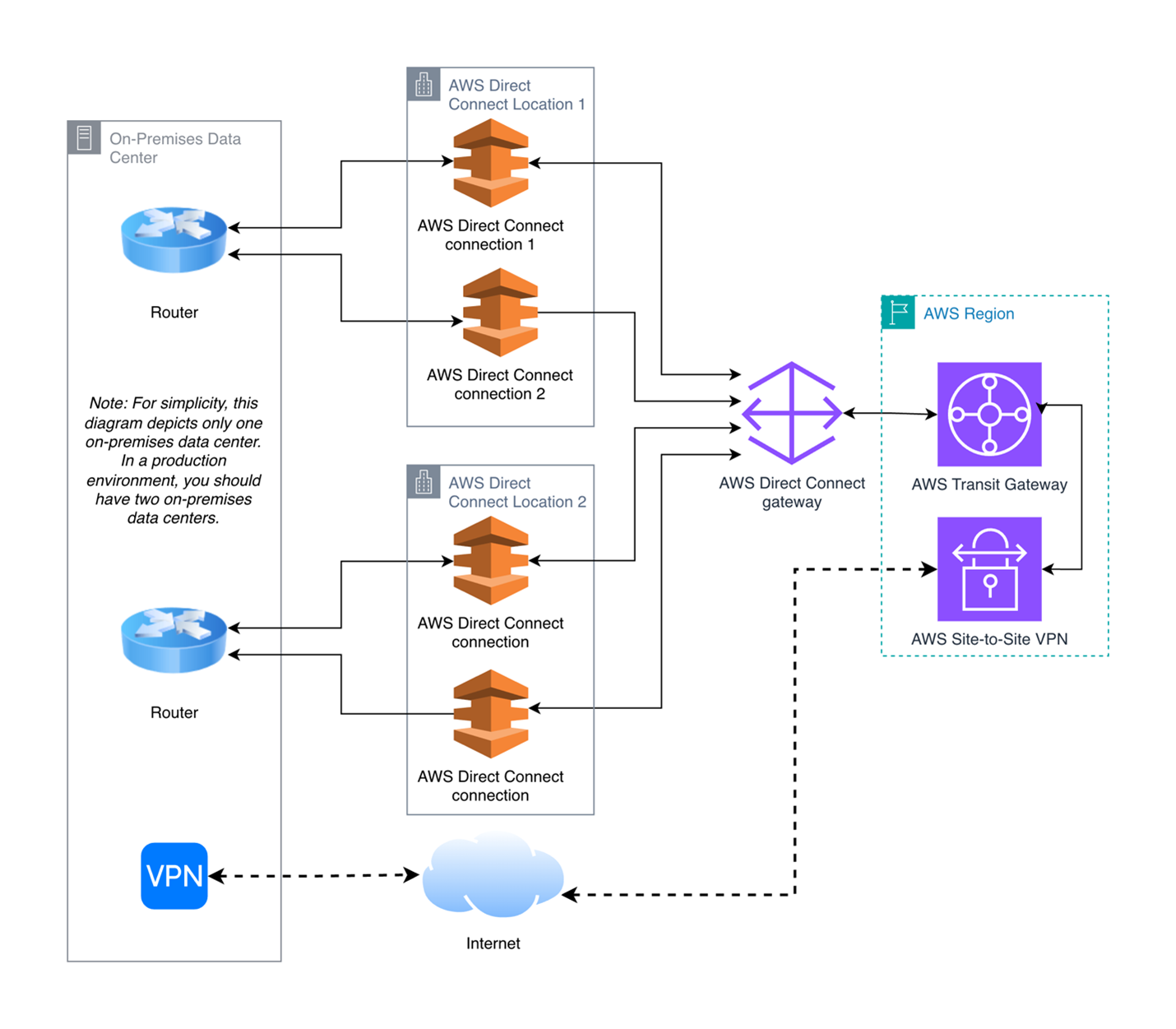
Figure 3: High-availability public safety connectivity architecture
Common network failures and testing
Connectivity architectures contain many components, and each one can fail. This creates the need for resilient and redundant designs. Several common failure modes can disrupt connectivity, and agencies should plan for them during normal operations.
A power failure or another incident that causes a device to fail will interrupt the path that depends on that device. ISP-based and Direct Connect-based connections also rely on multiple inline components such as routers, switches, and VPN appliances. Each of these represents a potential failure point. An ISP outage will disrupt all internet-based connectivity, and a fiber cut along a Direct Connect path will disable that circuit entirely.
Redundant connectivity can reduce the impact of these events, but agencies must test their designs regularly. As Amazon CTO Werner Vogels has stated, everything fails eventually. Controlled testing helps validate that failover works as expected and provides an opportunity to refine operational procedures.
Testing can be performed during planned maintenance windows. Common scenarios include:
- Simulating power failure by turning off a device
- Replicating an ISP outage by disconnecting the system from the provider network
- Testing a Direct Connect failure by unplugging the physical connection to the circuit
These exercises help agencies identify weaknesses and correct gaps before real incidents occur. Your AWS account team can assist with planning a safe and structured approach to failure testing. To learn more about failure testing and chaos engineering read about Chaos Engineering in the Cloud.
Monitoring and responding to failures
Not all outages result in a complete loss of connectivity. Some of the most difficult issues to diagnose are gray failures, where a network path remains available, but performance quietly degrades. For example, a Direct Connect link might start dropping a small percentage of packets due to an optical issue or failing hardware. The BGP session remains established, so routing appears healthy even though applications experience reduced throughput or intermittent timeouts.
These issues can be difficult to detect because many monitoring tools only indicate whether a connection is up or down. Agencies that depend on hybrid connectivity need visibility into partial degradation so they can identify when a path is unhealthy before it fully fails.
AWS provides tools to proactively monitor for these issues. Amazon CloudWatch Network Monitor, which includes a network health indicator (NHI), can help identify abnormal network behavior by actively probing each path. The Networking & Content Delivery Blog post Monitor hybrid connectivity with Amazon CloudWatch Network Synthetic Monitor explains how these tools can help determine whether a problem originates in the AWS network or in the customer network, and how they can support earlier detection and faster troubleshooting of gray failures.
By using these tools, organizations can identify and respond to degraded links before users or applications are significantly affected. That visibility is especially important for public safety workloads that depend on predictable and reliable access to AWS.
Conclusion
Building resilient connectivity is not only a best practice but a requirement for organizations that provide essential public safety services. As expectations for uptime and responsiveness continue to grow, agencies must invest in network designs that can withstand a wide range of failure scenarios. By selecting the right connectivity model, validating its performance through regular testing, and monitoring for both complete and partial failures, agencies can protect critical operations and maintain reliable public safety services.
To learn more about designing resilient hybrid connectivity for public safety workloads, explore the AWS Architecture Center, watch AWS networking sessions from re:Invent, or review additional JPS resilience stories on the AWS Public Sector Blog. Your AWS team can also help assess your current architecture and identify opportunities to strengthen continuity.