AWS Database Blog

Building a biological knowledge graph at Pendulum using Amazon Neptune
At Pendulum, we combine state-of-the-art genome sequencing, cell culturing, and manufacturing processes to produce Pendulum Glucose Control, the only medical probiotic clinically shown to lower blood glucose spikes for the dietary management of type 2 diabetes through the gut microbiome. Research and development at Pendulum requires the synthesis of a diverse set of rich data and information streams, and this year we undertook a project to aggregate much of our data into a single database, the Pendulum knowledge graph, which integrates publicly available information on bacterial metabolism with the DNA sequencing data we generate for our strains.

Deriving real-time insights over petabytes of time series data with Amazon Timestream
Time series data is one of the fastest growing categories across a variety of industry segments, such as application monitoring, DevOps, clickstream analysis, network traffic monitoring, industrial IoT, consumer IoT, manufacturing, and many more. Customers want to track billions of time series monitoring hundreds of millions of devices, industrial equipment, gaming sessions, streaming video sessions, […]

Collecting, storing, and analyzing your DevOps workloads with open-source Telegraf, Amazon Timestream, and Grafana
Customers asked us to integrate Telegraf with Amazon Timestream, a fast, scalable, serverless time series database service for IoT and operational applications, so we did. Thanks to the Timestream output plugin for Telegraf, you can now ingest metrics from Telegraf agent directly to Timestream.
Announcing the Amazon DocumentDB (with MongoDB compatibility) workshop
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6, 4.0 or 5.0 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without worrying about managing the underlying infrastructure. As a document […]

Exploring frequently asked questions with AWS Database Solutions Architects
July 2023: This post was reviewed for accuracy. At Amazon, we listen to our customers and work backward from your needs. Our AWS Database Specialist Solutions Architect team helps you architect your database landscape. In this post, we address 11 frequently asked questions with videos from our Database Specialist Solutions Architects. Let’s begin the learning […]

Setting up Amazon CloudWatch alarms for AWS DMS resources using the AWS CLI
For very large migrations, AWS Database Migration Service (AWS DMS) replication can run for hours or days depending on the data being replicated. It’s advisable to monitor the AWS DMS resources for a smooth migration. Monitoring your resources can help you detect anomalies and trigger notifications based on the threshold metrics configured. You can use […]
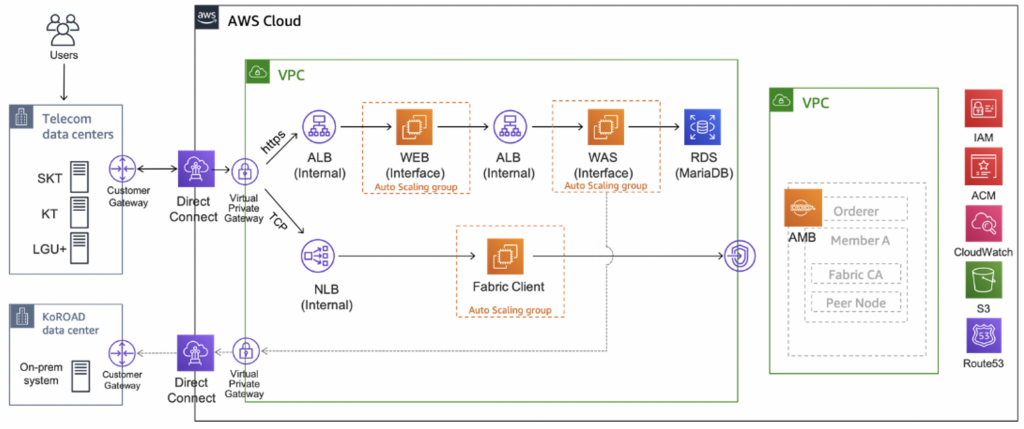
Building a secure digital ID using Amazon Managed Blockchain
This post discusses how these telecommunication companies used Amazon Managed Blockchain to build a universal mobile identity card platform and how this service works.

Getting started with Amazon DocumentDB (with MongoDB compatibility); Part 4 – using Amazon SageMaker notebooks
In this post, we demonstrate how to use Amazon SageMaker notebooks to connect to Amazon DocumentDB for a simple, powerful, and flexible development experience. We walk through the steps using the AWS Management Console, but also include an AWS CloudFormation template to add an Amazon SageMaker notebook to your existing Amazon DocumentDB environment.

Best practices for migrating Oracle database MERGE statements to Amazon Aurora PostgreSQL and Amazon RDS PostgreSQL
To migrate an Oracle database to Amazon Aurora with PostgreSQL compatibility, you usually need to perform both automated and manual tasks. The automated tasks involve schema conversion using AWS Schema Conversion Tool (AWS SCT) and data migration using AWS Database Migration Service (AWS DMS). The manual tasks involve post-AWS SCT migration touch-ups for certain database […]

Exploring Apache TinkerPop 3.4.8’s new features in Amazon Neptune
Amazon Neptune engine version 1.0.4.0 supports Apache TinkerPop 3.4.8, which introduces some new features and bug fixes. This post outlines these features, like the new elementMap() step and the improved behavior for working with map instances, and provides some examples to demonstrate their capabilities with Neptune. Upgrading your drivers to 3.4.8 should be straightforward and typically require no changes to your Gremlin code.