AWS Big Data Blog
Category: Customer Solutions

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

Automating IT support with AI: How Nexthink uses OpenSearch Service to power self-service issue resolution
In this post, we explore how Nexthink combined Amazon OpenSearch Service vector search, Amazon Bedrock, and infrastructure as code to power the Spark agent’s retrieval layer.

How Buildkite Operates Test Analytics at Massive Scale with Amazon MSK and Amazon Managed Service for Apache Flink
In this post, we explore how Buildkite uses Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink to power Test Engine’s streaming-first analytics architecture at scale.

How Zynga scaled multi-warehouse data governance with Amazon Redshift federated permissions
In this post, we walk through how Zynga adopted Amazon Redshift federated permissions and AWS IAM Identity Center to enforce consistent, tiered data access across provisioned and serverless Amazon Redshift environments without building custom synchronization pipelines.

How Amazon is moving to integrate catalogs to improve data discovery with Amazon SageMaker
Enterprises face challenges when teams create data assets outside of central data catalogs. It adds overhead for discovery, and limits collaboration. Amazon’s Business Data Technologies (BDT) team has built an enterprise data catalog Andes for sharing datasets under well-defined policies. However, teams created catalog of local datasets and other non-tabular assets such as dashboards and metrics, outside Andes. This made it difficult to discover all assets in a consolidated way. In this post, we share how Amazon.com is working to integrate catalogs by extending enterprise data catalog Andes with Amazon SageMaker.

How Smartsheet built Real-time Dynamic Filtering on Apache Flink reducing $40K/month in messaging costs
In this post, you learn how Smartsheet built a Real-time Dynamic Filtering (RDF) system on Amazon Managed Service for Apache Flink, cutting messaging costs by over $40,000 per month and improving live collaboration latency by 1.8x.

Detect and resolve HBase inconsistencies faster with AI on Amazon EMR
In this post, we show you how to build an AI-powered troubleshooting solution using Amazon OpenSearch Service vector search and intelligent analysis. This solution reduces HBase inconsistency resolution from hours to minutes and root cause identification from days to hours through natural language queries over operational data. This democratizes HBase troubleshooting capabilities across teams and reducing dependency on specialized expertise.

Enable real-time mainframe analytics with Precisely Connect and Amazon S3
In this post, we discuss how you can use Precisely Connect to enable real-time, direct replication of mainframe data to Amazon Simple Storage Service (Amazon S3), and how your organization can extend this foundation using Amazon S3 Tables for advanced analytics.

Enhancing Identity Intelligence with Babel Street Match and Amazon OpenSearch
This post explores how combining Babel Street Match with OpenSearch Service provides a solution that helps your organization to handle large-scale, multilingual data.
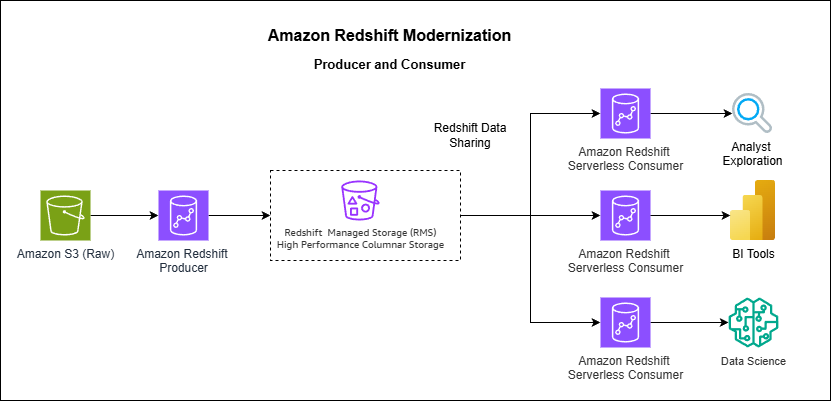
How Vanguard transformed analytics with Amazon Redshift multi-warehouse architecture
In this post, Vanguard’s Financial Advisor Services division describes how they evolved from a single Amazon Redshift cluster to a multi-warehouse architecture using data sharing and serverless endpoints to eliminate performance bottlenecks caused by exponential growth in ETL jobs, dashboards, and user queries.