การจัดการอุบัติการณ์คืออะไร
หัวข้อของหน้า
- การจัดการอุบัติการณ์คืออะไร
- เหตุใดการจัดการอุบัติการณ์จึงมีความสำคัญ
- เหตุการณ์ใดบ้างที่จำเป็นต้องมีการจัดการอุบัติการณ์
- การจัดการอุบัติการณ์ทำงานอย่างไร
- ขั้นตอนในกระบวนการจัดการอุบัติการณ์มีอะไรบ้าง
- แนวทางปฏิบัติที่ดีที่สุดในการจัดการอุบัติการณ์มีอะไรบ้าง
- AWS รองรับข้อกำหนดในการจัดการอุบัติการณ์ของคุณได้อย่างไร
การจัดการอุบัติการณ์คืออะไร
การจัดการอุบัติการณ์ (IM) เป็นกระบวนการที่ทีมไอทีใช้ในการตอบสนองต่อการหยุดชะงักของการบริการที่ไม่ได้วางแผนไว้ การหยุดชะงักที่ไม่คาดคิดเกิดขึ้นเนื่องจากเหตุการณ์ต่างๆ เช่น การสูญเสียหรือการลดประสิทธิภาพของการเชื่อมต่อเครือข่าย งานตามกำหนดการ (เช่น งานสำรองข้อมูล) ที่ไม่ได้ดำเนินการ หรือ API ที่ไม่ตอบสนอง กระบวนการจัดการอุบัติการณ์พยายามที่จะเรียกคืนการดำเนินงานตามปกติของบริการไอทีโดยเร็ว และลดผลกระทบทางธุรกิจ ระหว่างกระบวนการ ทีมตรวจพบและตรวจสอบเหตุการณ์ต่างๆ แก้ไขปัญหา และบันทึกขั้นตอนที่พวกเขาใช้ในการกู้บริการกลับมา
เหตุใดการจัดการอุบัติการณ์จึงมีความสำคัญ
การจัดการอุบัติการณ์จะเป็นแนวทางให้กับทีมไอทีเกี่ยวกับวิธีตอบสนองที่เหมาะสมที่สุดสำหรับเหตุการณ์ต่างๆ โดยสร้างระบบเพื่อให้ทีมไอทีสามารถบันทึกรายละเอียดที่เกี่ยวข้องทั้งหมดเพื่อเรียนรู้เพิ่มเติมในอนาคต คุณสามารถถือว่าการจัดการอุบัติการณ์เป็นแนวทางในการกู้คืนการดำเนินงานตามปกติอย่างรวดเร็วที่สุดเท่าที่จะเป็นไปได้ โดยมีผลกระทบต่อทั้งลูกค้าภายในและภายนอกองค์กรน้อยที่สุด
หากไม่มีการเตรียมระบบไว้ การกู้คืนจากเหตุการณ์ย่อมนำไปสู่ข้อผิดพลาดซ้ำๆ มีการใช้ทรัพยากรในทางที่ผิด และส่งผลเสียต่อองค์กรมากขึ้นอย่างหลีกเลี่ยงไม่ได้ ในลำดับต่อไป เราจะพูดคุยเกี่ยวกับวิธีที่คุณจะได้รับประโยชน์จากการจัดการอุบัติการณ์
ลดการเกิดอุบัติการณ์
เมื่อมีแนวทางที่จะปฏิบัติตามในกรณีที่เกิดเหตุการณ์ ทีมงานจะสามารถแก้ไขเหตุการณ์ต่างๆ ได้โดยเร็วที่สุด ในขณะเดียวกัน การจัดการอุบัติการณ์ยังช่วยลดการเกิดเหตุการณ์เมื่อเวลาผ่านไปอีกด้วย เมื่อคุณระบุความเสี่ยงตั้งแต่เนิ่นๆ ในกระบวนการ IM ก็จะช่วยลดโอกาสที่จะเกิดเหตุการณ์ในอนาคตได้ การบันทึกหลักฐานทางนิติวิทยาศาสตร์ของเหตุการณ์ไว้อย่างครบถ้วนจะช่วยในการแก้ไขเชิงรุก และช่วยป้องกันไม่ให้เหตุการณ์ที่คล้ายกันเกิดขึ้นในภายหลัง
ประสิทธิภาพการทำงานที่ดีขึ้น
เมื่อคุณใช้การตรวจสอบที่มีประสิทธิภาพและละเอียดอ่อนในการจัดการอุบัติการณ์ด้านไอที คุณจะสามารถระบุและตรวจสอบคุณภาพที่ลดลงแม้เพียงเล็กน้อยได้ อีกทั้งคุณจะพบวิธีใหม่ๆ ในการปรับปรุงประสิทธิภาพให้ดียิ่งขึ้นอีกด้วย เมื่อเวลาผ่านไป ทีมไอทีของคุณจะสามารถตัดสินคุณภาพของรูปแบบการระบุเหตุการณ์ของบริการ ซึ่งนำไปสู่การแก้ไขเชิงคาดการณ์และการบริการอย่างต่อเนื่อง
การทำงานร่วมกันอย่างมีประสิทธิภาพ
ทีมต่างๆ มักต้องทำงานร่วมกันเพื่อกู้คืนจากเหตุการณ์ คุณสามารถปรับปรุงการทำงานร่วมกันให้มีประสิทธิภาพมากขึ้นได้โดยการสรุปแนวทางการสื่อสารสำหรับทุกฝ่ายภายในเฟรมเวิร์กการตอบสนองต่อเหตุการณ์ คุณยังสามารถจัดการความรู้สึกของผู้มีส่วนเกี่ยวข้องได้อย่างมีประสิทธิภาพมากขึ้นอีกด้วย
เหตุการณ์ใดบ้างที่จำเป็นต้องมีการจัดการอุบัติการณ์
คำว่าการจัดการอุบัติการณ์ไม่ได้ใช้เฉพาะในงานด้านไอทีเท่านั้น นอกเหนือจากงานด้านไอที คุณจะได้ยินคำว่า IM ในงานสาขาต่างๆ เช่น บริการฉุกเฉิน การจัดการเหตุการณ์ขนาดใหญ่ และการปฏิบัติงานในโรงงาน
สำหรับบทความนี้ เราจะใช้คำว่า IM โดยหมายถึงภายในบริบทของการจัดการบริการไอที (ITSM) ในบริบทนี้ การจัดการอุบัติการณ์จะมุ่งเน้นไปที่กิจกรรมการจัดการที่เกี่ยวข้องกับคุณภาพของบริการและการบริการลูกค้า
ในลำดับต่อไป เราจะพูดคุยเกี่ยวกับกิจกรรมด้านไอทีต่างๆ ภายในขอบเขตของ IM ใน ITSM
เหตุการณ์ที่เกิดขึ้น
ภายในการจัดการอุบัติการณ์ เราสามารถกำหนดเหตุการณ์เป็นเหตุการณ์ที่ไม่คาดคิดซึ่งทำให้คุณภาพของบริการด้านไอทีที่คาดหวังหรือที่ตกลงกันไว้ลดลง ขนาดของเหตุการณ์อาจเล็กหรือใหญ่ก็ได้ และคุณอาจบ่งบอกถึงภาวะวิกฤตได้ ตัวอย่างเช่น คุณภาพของบริการที่ลดลงอาจเกิดขึ้นเพียงเล็กน้อยและจำกัดอยู่ในสถานที่ตั้งทางภูมิศาสตร์แห่งใดแห่งหนึ่ง หรือบริการอาจเกิดการขัดข้องทั้งระบบในหลายภูมิภาค
ปัญหา
ปัญหาหมายถึงสาเหตุที่แท้จริงของเหตุการณ์ ซึ่งค้นพบหลังจากการสอบสวนเพิ่มเติม และจำเป็นสำหรับการแก้ไขทั้งเหตุการณ์ ตัวอย่างเช่น หากเว็บเซิร์ฟเวอร์ทำงานช้า ปัญหาอาจเป็นเพราะการกำหนดค่าเราเตอร์ไม่ถูกต้องที่ศูนย์ข้อมูลหรือสายเคเบิลเครือข่ายขาดที่บริเวณขอบเขต
การเปลี่ยนแปลง
ใน IM การเปลี่ยนแปลงหมายถึงเมื่อกำลังเปลี่ยนแปลงบริการเพื่อปรับปรุงคุณภาพหรือเพิ่มคุณสมบัติใหม่ๆ เป็นต้น ในช่วงระยะเวลาการเปลี่ยนแปลง จะต้องจัดการการเปลี่ยนผ่านอย่างระมัดระวังเพื่อหลีกเลี่ยงหรือลดการหยุดชะงักในการดำเนินธุรกิจตามปกติ ซึ่งรวมถึงการให้คำแนะนำแก่ลูกค้าเกี่ยวกับการหยุดชะงักของบริการที่คาดไว้หรือที่อาจเกิดขึ้นได้
คำขอรับบริการ
คำขอรับบริการคือคำขอที่เริ่มโดยลูกค้าภายในขอบเขตของข้อกำหนดข้อตกลงระหว่างผู้ให้บริการและลูกค้า คำขอดังกล่าวควรได้รับการดำเนินการโดยไม่กระทบต่อการดำเนินงานตามปกติ
การจัดการอุบัติการณ์ทำงานอย่างไร
การจัดการอุบัติการณ์ใช้ชุดกระบวนการที่บันทึกไว้ ซึ่งสรุปอย่างชัดเจนถึงสิ่งที่ต้องดำเนินการเพื่อลดผลกระทบในแง่ลบและระยะเวลาที่งานไอทีหยุดชะงัก นอกเหนือจากการจัดการด้านเทคนิคสำหรับเหตุการณ์ผิดปกติที่เกิดขึ้นแล้ว ยังรวมถึงการจัดการความคาดหวังของลูกค้า ผู้ใช้ และผู้มีส่วนเกี่ยวกับในระหว่างที่เกิดเหตุการณ์อีกด้วย
สำหรับลูกค้า ข้อตกลงระดับการให้บริการ (SLA) จะระบุการรับประกันเวลาทำงานที่คาดหวังได้ เวลาในการแก้ไขปัญหา และช่องทางการสื่อสารในกรณีที่เกิดเหตุการณ์ต่าง ๆ ไว้อย่างชัดเจน โดยจะต้องมีการจัดการอุบัติการณ์ที่ครอบคลุมในส่วนของผู้ให้บริการ เพื่อให้เป็นไปตามข้อกำหนดและเงื่อนไขใน SLA
เฟรมเวิร์กการจัดการอุบัติการณ์ด้านไอที
มีเฟรมเวิร์กต่าง ๆ ที่องค์กรใช้เพื่อจำลอง IM ของตนเอง 2 ตัวอย่าง ได้แก่ การจัดการอุบัติการณ์จาก IT Infrastructure Library (ITIL) 4 และเฟรมเวิร์กการรักษาความปลอดภัยทางไซเบอร์จาก National Institute of Standards and Technology (NIST) คุณอาจนำเฟรมเวิร์กเหล่านี้มาใช้ตามที่มีอยู่หรือขยายเพื่อปรับให้เข้ากับสภาพแวดล้อมทางธุรกิจ บริการ และมาตรฐานการสื่อสารของลูกค้าและผู้มีส่วนเกี่ยวข้อง
ซอฟต์แวร์การจัดการอุบัติการณ์มักนำมาใช้เพื่อปรับใช้เฟรมเวิร์กภายในองค์กร ส่วนจะใช้เฟรมเวิร์กใดนั้น ก็ขึ้นอยู่กับบริการที่นำเสนอ
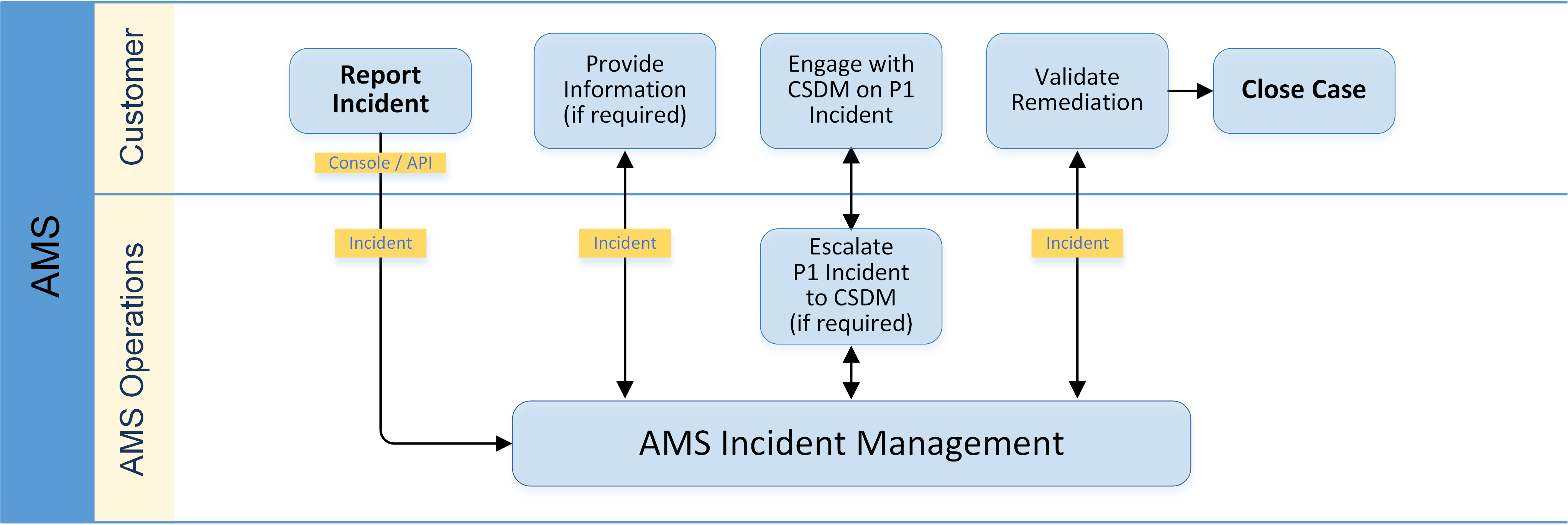
ขั้นตอนในกระบวนการจัดการอุบัติการณ์มีอะไรบ้าง
ขั้นตอนที่เกี่ยวข้องกับกระบวนการจัดการอุบัติการณ์นั้นจะขึ้นอยู่กับเฟรมเวิร์กที่ใช้ภายในองค์กร ในลำดับต่อไป เราจะพูดคุยเกี่ยวกับขั้นตอนหลัก ๆ ในเฟรมเวิร์กวงจรการจัดการอุบัติการณ์ที่พบได้บ่อย
ระบุความเสี่ยง
การระบุแอสเซท ระบบ ข้อมูล และทรัพยากรอื่น ๆ ที่สำคัญจะเป็นการบ่งชี้ว่าจุดใดที่ธุรกิจมีความเสี่ยงมากที่สุด ในบริบทของการให้บริการแก่ลูกค้า จะเป็นการระบุระบบและแอสเซทที่มีค่าที่สุดของลูกค้า
ปกป้องแอสเซท
เมื่อระบุแอสเซทแล้ว องค์กรจะเสริมการรักษาความปลอดภัยและการควบคุมประสิทธิภาพให้แข็งแกร่งยิ่งขึ้น ตัวอย่างเช่น สามารถติดตั้งใช้งานแอปพลิเคชันได้ในหลายภูมิภาคเพื่อความพร้อมใช้งานอย่างต่อเนื่องในกรณีที่ระบบขัดข้องในระดับภูมิภาค
ตรวจจับเหตุการณ์
ต้องมีระบบในการติดตามสถานะของแอสเซทที่สำคัญเพื่อให้สามารถระบุเหตุการณ์ได้แบบเรียลไทม์ องค์กรจะต้องดำเนินการเชิงรุกในการติดตามความผิดปกติ ซึ่งโดยปกติแล้วไม่แนะนำให้เรียนรู้จากเหตุการณ์ขัดข้องที่ลูกค้ารายงานมาเอง ควรเน้นไปที่การแก้ไขเชิงรุก
ตอบสนองต่อเหตุการณ์ที่เกิดขึ้น
เมื่อตรวจพบเหตุการณ์แล้ว คุณจะต้องระงับการหยุดชะงักนั้นทันที หากไม่สามารถทำได้ คุณสามารถปฏิบัติตามกระบวนการเพื่อตีกรอบหรือจำกัดผลกระทบที่เกิดขึ้น คุณอาจต้องเปิดใช้งานระบบรองเพื่อให้สามารถดำเนินงานต่อได้แม้ว่าจะไม่มีวิธีแก้ไขอย่างเร่งด่วนก็ตาม ส่วนใหญ่อาจเป็นไปโดยอัตโนมัติ ทั้งนี้ขึ้นอยู่กับลักษณะของเหตุการณ์และเครื่องมือการจัดการอุบัติการณ์ที่ใช้อยู่ในปัจจุบัน
กู้คืนจากเหตุการณ์ที่เกิดขึ้น
ในระยะการกู้คืน จะเริ่มทำการวิเคราะห์เหตุการณ์ คุณบันทึกบทเรียนที่ได้เรียนรู้ วางแผนการตอบสนองที่ดียิ่งขึ้น และแก้ไขปัญหาและกระบวนการต่าง ๆ เหตุการณ์ร้ายแรงอาจต้องใช้ความพยายามอย่างมากในการกู้คืน รูปภาพต่อไปนี้แสดงให้เห็นถึงหนึ่งในกระบวนการจัดการอุบัติการณ์ที่ Amazon Web Services (AWS) ใช้

แนวทางปฏิบัติที่ดีที่สุดในการจัดการอุบัติการณ์มีอะไรบ้าง
แนวปฏิบัติที่ดีที่สุดช่วยให้องค์กรดำเนินงานในระดับที่มีศักยภาพสูงสุดภายในหน่วยธุรกิจหรือพื้นที่เชิงกลยุทธ์ที่กำหนด เมื่อปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดในระบบการจัดการอุบัติการณ์ คุณจะสามารถให้บริการที่ดีที่สุดแก่ลูกค้าได้
พัฒนานโยบายการยกระดับ
คุณควรสามารถจัดหมวดหมู่เหตุการณ์ต่าง ๆ ตามลำดับความสำคัญและความรุนแรงเพื่อเป็นแนวทางในการกำหนดกรอบเวลา การแก้ไข และการสืบสวน คุณควรใช้นโยบายการยกระดับเมื่อการตอบสนองต่อเหตุการณ์ไม่เป็นไปตามที่คาดไว้ หรือหากเกิดเหตุการณ์ร้ายแรงที่มีลำดับความสำคัญหรือความรุนแรงสูง หากไม่มีนโยบายเหล่านี้ ทีมของคุณอาจเสียเวลาในการตัดสินใจว่าจะติดต่อใครและจะทำอย่างไร
วางแผนการสื่อสารโดยละเอียด
ผู้มีส่วนเกี่ยวข้องตั้งแต่ทีมไอทีไปจนถึงผู้ใช้ปลายทางของคุณควรได้รับแจ้งเกี่ยวกับสถานะของเหตุการณ์ที่เกิดขึ้น การมีช่องทางการสื่อสารที่ชัดเจนก็เป็นประโยชน์เช่นกัน เพื่อให้ผู้ที่ได้รับผลกระทบรู้ว่าควรไปที่ใดเพื่อหาข้อมูลอัปเดตหรือรายงานเหตุการณ์ใหม่ ๆ เมื่อมีแผนการสื่อสารที่ชัดเจน คุณจะสามารถสร้างความไว้วางใจและหลีกเลี่ยงการตำหนิที่ผิดพลาดได้ เหตุการณ์ที่สำคัญจะได้รับการจัดการด้วยระบบการทูตเสมอ
วิเคราะห์สาเหตุของปัญหา
หลังจากแก้ไขเหตุการณ์แล้ว คุณควรทำการวิเคราะห์สาเหตุที่แท้จริงเพื่อทำความเข้าใจว่าเหตุใดจึงเกิดเหตุการณ์ดังกล่าวขึ้นตั้งแต่แรก ซึ่งจะช่วยค้นหาช่องว่างหรือช่องโหว่ในระบบ ซึ่งคุณสามารถจัดการเพื่อป้องกันเหตุการณ์ที่คล้ายกันที่จะเกิดขึ้นในอนาคตได้ บทเรียนที่ได้เรียนรู้จากแต่ละเหตุการณ์มีประโยชน์ในการปรับปรุงโครงสร้างพื้นฐานและกระบวนการด้านไอทีอย่างต่อเนื่อง
นำแนวทางปฏิบัติด้าน Chaos Engineering มาใช้
วิศวกรรมความโกลาหล (Chaos Engineering) เป็นสาขาหนึ่งของวิศวกรรมซอฟต์แวร์ที่ตั้งใจทำให้ระบบอยู่ภายใต้สภาวะที่หยุดชะงัก เช่น เซิร์ฟเวอร์ล้มเหลว เวลาแฝงของเครือข่าย หรือข้อจำกัดของทรัพยากร การสร้างความโกลาหลในระบบจะทดสอบความยืดหยุ่น และยังเสริมสร้างความเข้มแข็งให้กับกระบวนการตอบสนองและการจัดการเหตุการณ์ขององค์กรอีกด้วย ซึ่งเป็นเทคนิคที่คล้ายกับการนำการแฮ็กอย่างมีจริยธรรมมาใช้ในการจัดการอุบัติการณ์เกี่ยวกับความปลอดภัยทางไซเบอร์
AWS รองรับข้อกำหนดในการจัดการอุบัติการณ์ของคุณได้อย่างไร
AWS มีบริการต่าง ๆ มากมายที่ช่วยให้องค์กรสามารถจัดการอุบัติการณ์ได้อย่างมีประสิทธิภาพภายใน AWS และสภาพแวดล้อมแบบไฮบริด
การตรวจจับและการตอบสนองเหตุการณ์ของ AWS ให้ลูกค้า AWS Enterprise Support ได้ตรวจสอบเชิงรุกและจัดการอุบัติการณ์สำหรับเวิร์กโหลดที่เลือก ด้วยการทำงานร่วมกับผู้เชี่ยวชาญ คุณจะสามารถกำหนดเกณฑ์ชี้วัดที่สำคัญ การแจ้งเตือน และตารางการจัดลำดับความสำคัญสำหรับระบบการจัดการอุบัติการณ์ด้านไอทีเพื่อเร่งการกู้คืนในกรณีที่เกิดเหตุการณ์ได้
AWS Managed Services (AMS) ช่วยปกป้องข้อมูลขององค์กร ตลอดจนโครงสร้างพื้นฐานของคุณด้วยความสามารถในการตอบสนองและแก้ไขเหตุการณ์ของ AWS คุณสามารถใช้ AMS เป็นวิธีในการว่าจ้างบุคคลภายนอกให้ดูแลจัดการอุบัติการณ์ด้านไอทีของ AWS เพื่อที่องค์กรของคุณจะได้มุ่งเน้นไปที่ธุรกิจหลัก ต่อไปนี้คือสิ่งที่คุณสามารถทำได้ด้วย AMS
-
ขอความช่วยเหลือเกี่ยวกับปัญหาการดำเนินงานและขอความช่วยเหลือได้ตลอดเวลาผ่าน AWS Support Center ในคอนโซล AWS
-
เข้าถึงการสนับสนุนได้ตลอด 24 ชั่วโมงทุกวัน โดยที่เวลาตอบกลับจะขึ้นอยู่กับระดับบริการของบัญชีที่คุณเลือก (Plus, Premium)
-
รับการแจ้งเตือนในเชิงรุกเกี่ยวกับสัญญาณเตือนและคำถามที่สำคัญโดยใช้กลไกเดียวกัน
ในฐานะส่วนหนึ่งของเฟรมเวิร์ก AWS Well-Architected เรายังให้คำแนะนำที่ชัดเจนสำหรับการจัดการอุบัติการณ์บนระบบคลาวด์อีกด้วย ซึ่งเป็นแหล่งข้อมูลที่ดีในการช่วยวางแผนการจัดการอุบัติการณ์สำหรับองค์กร โดยนำเสนอบริการด้านไอทีของตนเองที่ใช้บริการของ AWS Cloud คู่มือการตอบสนองต่ออุบัติการณ์ด้านความปลอดภัยของ AWS เป็นอีกหนึ่งข้อมูลที่เป็นประโยชน์สำหรับเหตุการณ์ที่เกี่ยวข้องกับการรักษาความปลอดภัย
เริ่มต้นใช้งานการจัดการอุบัติการณ์บน AWS โดยสร้างบัญชีวันนี้
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages