O que é rastreamento distribuído?
Tópicos da página
- O que é rastreamento distribuído?
- Quais são os benefícios do uso do rastreamento distribuído?
- Quais são os diferentes tipos de rastreamento distribuído?
- Como o rastreamento distribuído de ponta a ponta funciona em arquiteturas de microsserviços?
- O que são padrões de rastreamento distribuído?
- Qual é a diferença entre o rastreamento distribuído e o registro em log?
- Quais são os desafios do rastreamento distribuído?
- De que maneira a AWS pode apoiar seus requisitos de rastreamento distribuído?
O que é rastreamento distribuído?
O rastreamento distribuído consiste na observação de solicitações de dados conforme elas passam por um sistema distribuído. A arquitetura de microsserviços moderna geralmente conta com vários componentes pequenos e independentes, os quais se comunicam e trocam dados constantemente usando APIs para a realização de trabalhos complexos. Com o rastreamento distribuído, os desenvolvedores podem rastrear, ou acompanhar visualmente, o caminho de uma solicitação por diferentes microsserviços. Esta visibilidade auxilia na resolução de erros ou na correção de bugs e problemas de performance.
Quais são os benefícios do uso do rastreamento distribuído?
Os desenvolvedores de software podem implementar sistemas de rastreamento distribuído em praticamente qualquer ambiente nativo da nuvem, bem como registrar rastreamentos distribuídos gerados pelas aplicações em nuvem. Além disso, as ferramentas de rastreamento são compatíveis com diversas linguagens de programação e conjuntos de software, permitindo que as equipes de software monitorem e coletem dados de performance para diferentes aplicações na mesma plataforma.
As equipes de desenvolvimento usam o rastreamento distribuído para aprimorar a observabilidade, bem como para resolver problemas de performance que as ferramentas convencionais de depuração e monitoramento de software não conseguem solucionar.
A seguir, apresentamos mais benefícios do rastreamento distribuído.
Aceleração da resolução de problemas de software
As aplicações modernas dependem de inúmeros microsserviços para trocar dados e atender a solicitações de serviço em sistemas distribuídos. A resolução de problemas de performance em uma arquitetura baseada em microsserviços é significativamente mais desafiadora do que em uma aplicação de software monolítica. Ao contrário de uma aplicação monolítica, a causa raiz de um problema de software específico pode não ser aparente, visto que as interações sobrepostas e complexas entre múltiplos módulos de software podem dificultar o diagnóstico de problemas.
Com o rastreamento distribuído, as equipes de software podem monitorar dados que passam por caminhos complexos conectando vários microsserviços e armazenamento de dados. Com ferramentas de rastreamento distribuído, as equipes de software rastreiam solicitações e visualizam caminhos de propagação de dados com precisão. As equipes de software podem resolver problemas de performance com agilidade e minimizar interrupções nos serviços.
Melhoria da colaboração entre desenvolvedores
Diversos desenvolvedores costumam estar envolvidos no desenvolvimento de uma aplicação em nuvem, sendo cada um responsável por um ou mais microsserviços. O processo de desenvolvimento de software torna-se mais lento se os desenvolvedores não puderem realizar o rastreamento dos dados trocados pelos microsserviços. Com os sistemas de rastreamento distribuído, os desenvolvedores podem colaborar fornecendo dados de telemetria, como logs e rastreamentos, para cada solicitação de serviço realizada pelo microsserviço. Os desenvolvedores podem responder de forma precisa a bugs e outros problemas de software detectados durante as fases de teste e de produção.
Redução do tempo de colocação no mercado
As organizações que implantam plataformas de rastreamento distribuído podem simplificar e acelerar as iniciativas destinadas ao lançamento de aplicações de software para usuários finais. As equipes de software analisam rastreamentos distribuídos para obter insights que aceleram o desenvolvimento de software, minimizam os custos de desenvolvimento, compreendem os comportamentos dos usuários e melhoram a prontidão para o mercado.
Quais são os diferentes tipos de rastreamento distribuído?
As equipes de software usam ferramentas de rastreamento distribuído para monitorar, analisar e otimizar aplicações.
Rastreamento de código
O rastreamento de código é um processo de software que inspeciona o fluxo de códigos-fonte em uma aplicação ao executar uma função específica. Isso auxilia desenvolvedores na compreensão do fluxo lógico do código e na identificação de problemas desconhecidos. Por exemplo, os desenvolvedores usam o rastreamento de código para validar que a solicitação de serviço invocou etapas para consultar um banco de dados. Caso algumas funções do software não forneçam uma resposta, o sistema de rastreamento coletará o status de erro apropriado e destacará o tempo de resposta.
Rastreamento de programas
O rastreamento de programas é um método no qual os desenvolvedores podem examinar os endereços de instruções e variáveis chamadas por uma aplicação ativa. Quando uma aplicação de software é executada, ela processa cada linha de código que reside em um espaço de memória alocado específico. A aplicação também processa as variáveis armazenadas na memória da máquina. A inspeção de alterações nas memórias de programas e de dados é um desafio sem o uso de uma ferramenta automatizada. Com o rastreamento de programas, as equipes de software podem diagnosticar problemas de performance profundamente enraizados, como transbordamento de dados, consumo excessivo de recursos e operações lógicas de bloqueio.
Rastreamento de ponta a ponta
Com o rastreamento de ponta a ponta as equipes de desenvolvimento podem rastrear a transformação de dados ao longo do caminho da solicitação de serviço. Quando uma aplicação inicia uma solicitação, ela envia dados a outros componentes de software para fornecer continuidade ao processamento. Os desenvolvedores usam ferramentas de rastreamento para monitorar e compilar as alterações que os dados críticos sofrem de ponta a ponta. Isso permite uma visão centrada na aplicação sobre o fluxo de solicitações presente na aplicação.
Como o rastreamento distribuído de ponta a ponta funciona em arquiteturas de microsserviços?
Ao usar aplicações, os usuários iniciam solicitações de serviço e diferentes componentes da aplicação processam a solicitação.
Considere um usuário que faz a reserva de um ingresso em uma aplicação de compra de ingressos de cinema on-line. O usuário informa seus dados de contato, detalhes do filme e informações de pagamento e seleciona Reservar agora. Uma solicitação é criada e enviada para:
-
O microsserviço A que valida os dados inseridos pelo usuário.
-
O microsserviço B que recebe os dados de A e cria um registro no banco de dados de clientes.
-
O microsserviço C que recebe os dados de B e valida o pagamento.
-
O microsserviço D que coleta os dados de C, faz a alocação de um assento e gera os dados do ingresso de cinema.
-
O microsserviço E que coleta os dados de D e gera um arquivo em PDF formatado do ingresso.
Uma resposta contendo o PDF do ingresso retorna, então, pela cadeia de microsserviços, de E para D, C, B e A, até que finalmente alcance o usuário. O exemplo apresentado acima é simples. Uma solicitação geralmente percorre dezenas de microsserviços e até mesmo cadeias de componentes de software de entidades externas à aplicação. Isso torna o processo cada vez mais complexo.
Os sistemas de rastreamento distribuído monitoram essas interações de solicitações de serviço com outros microsserviços e componentes de software no ambiente de computação distribuída. Um rastreamento distribuído representa a linha do tempo e todas as ações que ocorrem entre a geração da solicitação e o recebimento da resposta. As equipes de software usam o rastreamento para acompanhar o fluxo de dados por meio de vários microsserviços com os quais a solicitação inicial interage.
Intervalo
Ao processar uma solicitação de serviço, uma aplicação pode realizar diversas ações. Essas ações são representadas como intervalos no rastreamento distribuído. Por exemplo, um intervalo pode ser uma chamada de API, autenticação de usuário ou a habilitação de acesso ao armazenamento. Se uma única solicitação resultar em várias ações, o intervalo inicial (ou principal) pode se ramificar em vários intervalos secundários. Essas camadas aninhadas de intervalos principais e secundários formam uma representação lógica contínua das etapas seguidas para concluir a solicitação de serviço.
ID de rastreamento
O sistema de rastreamento distribuído atribui um ID exclusivo a cada solicitação para fins de acompanhamento. Cada intervalo herda o mesmo ID de rastreamento da solicitação original à qual pertence. Os intervalos também são marcados com um ID de intervalo exclusivo que ajuda o sistema de rastreamento a consolidar os metadados, os logs e as métricas coletados.
Coleta de métricas
À medida que cada intervalo passa por diferentes microsserviços, ele anexa métricas que fornecem aos desenvolvedores insights profundos e precisos sobre o comportamento do software. É possível coletar taxa de erro, carimbo de data/hora, tempo de resposta e outros metadados com os intervalos. Após o rastreamento completar um ciclo inteiro, a ferramenta de rastreamento distribuído consolida todos os dados coletados.
Por exemplo, uma chamada de API é avaliada por meio do tempo de resposta, status de erro e do detalhamento de funções secundárias atendidas por diversos serviços de terceiros. A ferramenta de rastreamento transforma os dados em elementos visuais, destacando os principais indicadores e fornecendo resumos da performance. Dessa forma, engenheiros de confiabilidade de sites podem identificar erros rapidamente, inspecionar elementos de dados críticos e colaborar com equipes de desenvolvimento para corrigir problemas de performance e garantir a conformidade com acordos de serviço (SLAs).

O que são padrões de rastreamento distribuído?
Os padrões de rastreamento distribuído fornecem uma estrutura comum e ferramentas de software para desenvolvedores. Estes padrões permitem monitorar, visualizar e analisar solicitações de serviço em ambientes de aplicações modernos. Ao padronizar o fluxo de trabalho de rastreamento distribuído, as equipes de software podem instrumentar o rastreamento de solicitações sem ficarem sujeitas à dependência de fornecedor.
As seções apresentadas a seguir descrevem padrões criados para possibilitar a interoperabilidade durante a execução do rastreamento distribuído.
OpenTracing
O OpenTracing é um padrão de rastreamento distribuído de código aberto desenvolvido pela Cloud Native Computing Foundation (CNCF). O OpenTracing se concentra em possibilitar que os desenvolvedores gerem rastreamentos por meio de uma API de instrumentação. Isso permite que os desenvolvedores gerem rastreamentos distribuídos de diferentes partes da base de código, biblioteca ou outras dependências.
OpenCensus
O OpenCensus é composto por bibliotecas em diversas linguagens capazes de extrair métricas de software e encaminhá-las a sistemas de backend para análise. Os desenvolvedores podem usar a API fornecida para gerenciar como os rastreamentos são gerados e coletados. Ao contrário do OpenTracing, os desenvolvedores trabalham com o OpenCensus usando um único repositório de projeto, em vez de bases de código e bibliotecas individuais.
OpenTelemetry
O OpenTelemetry unifica o OpenTracing e o OpenCensus. Ele combina os melhores recursos de ambos os padrões para fornecer uma estrutura de rastreamento distribuído abrangente. O OpenTelemetry fornece kits de desenvolvimento de software extensivos, APIs, bibliotecas e outras ferramentas de instrumentação para implementar o rastreamento distribuído com mais facilidade.
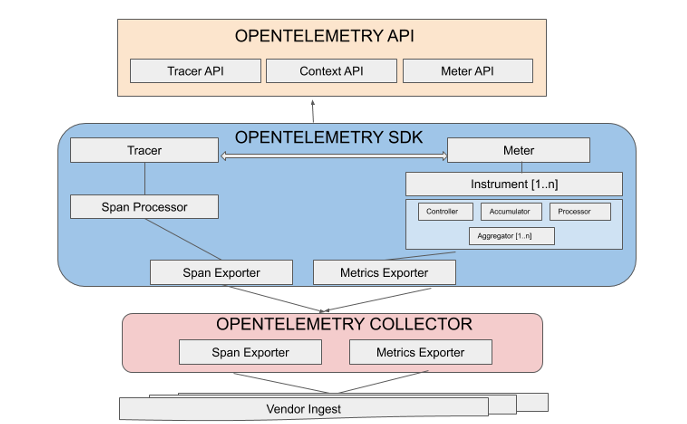
Qual é a diferença entre o rastreamento distribuído e o registro em log?
O registro em log é a prática de gravar eventos específicos que ocorrem durante a execução de uma aplicação. As ferramentas de registro em log coletam eventos com carimbo de data/hora, como erros do sistema, interações do usuário, status de comunicação e outras métricas, para auxiliar equipes de desenvolvimento na detecção de anomalias de sistema. Em geral, existem dois tipos de registro em log:
-
O registro em log centralizado coleta todas as atividades gravadas e as armazena em um único local.
-
O registro em log distribuído armazena arquivos de log em locais distintos na nuvem.
Ambos os métodos de registro em log fornecem uma visão estática de incidentes que mostram aos desenvolvedores o que aconteceu na aplicação. Por outro lado, o rastreamento distribuído fornece uma trilha de auditoria que esclarece o motivo de um incidente ter ocorrido por meio da correlação de diversos dados de telemetria coletados ao longo do período de uma solicitação de serviço. O rastreamento distribuído pode usar registros em log e outros métodos de coleta de dados para rastrear uma solicitação de serviço específica.
Quais são os desafios do rastreamento distribuído?
O rastreamento distribuído simplificou as iniciativas dos desenvolvedores no diagnóstico, na depuração e na correção de problemas de software. Apesar disso, os desafios apresentados a seguir permanecem e as equipes de software devem estar atentas a eles ao escolher ferramentas de rastreamento.
Instrumentação manual
Algumas ferramentas de rastreamento exigem que as equipes de software realizem a instrumentação manual de seus códigos para gerar os rastreamentos necessários. Quando os desenvolvedores modificam códigos para rastrear solicitações, existem riscos de erros de codificação que afetam as versões em produção. Além disso, a ausência de automação torna o rastreamento complexo, o que gera atrasos e pode resultar em uma coleta de dados imprecisa.
Abrangência de frontend limitada
Os desenvolvedores podem não ser capazes de obter uma supervisão completa dos problemas de performance se as ferramentas de rastreamento estiverem restritas à análise de backend. Em alguns casos, o sistema de rastreamento distribuído só começa a coletar dados quando o primeiro serviço de backend recebe a solicitação. Isso significa que os desenvolvedores não podem detectar e inspecionar problemas decorrentes de serviços de frontend durante a sessão de usuário correspondente.
Amostragem aleatória
Algumas ferramentas não permitem que as equipes de software priorizem o rastreamento, limitando a observabilidade a rastreamentos amostrados aleatoriamente. Com dados de amostra limitados, as organizações precisam de abordagens adicionais de solução de problemas relacionados ao software para identificar problemas críticos que não são detectados pela ferramenta de rastreamento.
De que maneira a AWS pode apoiar seus requisitos de rastreamento distribuído?
O AWS X-Ray é uma plataforma de rastreamento distribuído que auxilia desenvolvedores de software no rastreamento de solicitações de usuários e na identificação de gargalos em suas aplicações em nuvem. As organizações usam o X-Ray para visualizar métricas de aplicações e aumentar a disponibilidade da workloads. Com o AWS X-Ray, você pode:
-
Realizar a integração com todas as aplicações em execução no Amazon Elastic Compute Cloud (EC2), Amazon EC2 Container Service (Amazon ECS), AWS Lambda e AWS Elastic Beanstalk.
-
Definir a taxa de amostragem apropriada para fornecer visibilidade de ponta a ponta para os rastreamentos.
-
Visualizar os dados agregados com um mapa de serviços que exibe métricas principais, como latência e taxas de falha.
Comece a usar o rastreamento distribuído na AWS ao criar uma conta hoje mesmo.
Próximas etapas na AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages