Apa itu Klasifikasi Teks?
Topik halaman
- Apa itu Klasifikasi Teks?
- Apa Saja Keuntungan Klasifikasi Teks?
- Apa Saja Kasus Penggunaan Klasifikasi Teks?
- Apa Saja Pendekatan untuk Klasifikasi Teks?
- Bagaimana Anda Mengevaluasi Performa Klasifikasi Teks?
- Bagaimana Anda Mengimplementasikan Klasifikasi Teks?
- Apa Saja Tantangan dalam Klasifikasi Teks?
- Bagaimana AWS Dapat Membantu Persyaratan Klasifikasi Teks Anda?
Apa itu Klasifikasi Teks?
Klasifikasi teks adalah proses menetapkan kategori yang telah ditentukan untuk dokumen teks terbuka menggunakan sistem kecerdasan buatan dan machine learning (AI/ML). Banyak organisasi memiliki arsip dokumen yang besar dan alur kerja bisnis yang terus-menerus menghasilkan dokumen dalam skala besar—seperti dokumen hukum, kontrak, dokumen penelitian, data yang dihasilkan pengguna, dan email. Klasifikasi teks adalah langkah pertama untuk mengatur, menyusun, dan mengategorikan data ini untuk analitik lebih lanjut. Klasifikasi teks memungkinkan pelabelan dan penandaan dokumen otomatis. Klasifikasi teks menghemat ribuan jam bagi organisasi Anda yang seharusnya Anda perlukan untuk membaca, memahami, dan mengklasifikasikan dokumen secara manual.
Apa Saja Keuntungan Klasifikasi Teks?
Organisasi menggunakan model klasifikasi teks untuk alasan berikut.
Meningkatkan Akurasi
Model klasifikasi teks mengategorikan teks secara akurat dengan sedikit atau tanpa pelatihan tambahan. Model tersebut membantu organisasi mengatasi kesalahan yang mungkin dilakukan manusia saat mengklasifikasikan data tekstual secara manual. Selain itu, sistem klasifikasi teks lebih konsisten daripada manusia ketika menetapkan tanda ke data teks di berbagai topik.
Memberikan Analitik Waktu Nyata
Organisasi menghadapi tekanan waktu ketika memproses data teks secara waktu nyata. Dengan algoritma klasifikasi teks, Anda dapat mengambil wawasan yang dapat ditindaklanjuti dari data mentah dan merumuskan respons langsung. Sebagai contoh, organisasi dapat menggunakan sistem klasifikasi teks untuk menganalisis umpan balik pelanggan dan merespons permintaan yang mendesak dengan segera.
Menskalakan Tugas Klasifikasi Teks
Organisasi sebelumnya mengandalkan sistem manual atau berbasis aturan untuk mengklasifikasikan dokumen. Metode ini lambat dan mengonsumsi sumber daya yang berlebihan. Dengan klasifikasi teks machine learning, Anda dapat memperluas upaya kategorisasi dokumen di seluruh departemen secara lebih efektif untuk mendukung pertumbuhan organisasi.
Menerjemahkan Bahasa
Organisasi dapat menggunakan pengklasifikasi teks untuk deteksi bahasa. Model klasifikasi teks dapat mendeteksi bahasa asal dalam percakapan atau permintaan layanan dan mengarahkannya ke tim masing-masing.
Apa Saja Kasus Penggunaan Klasifikasi Teks?
Organisasi menggunakan klasifikasi teks untuk meningkatkan kepuasan pelanggan, produktivitas karyawan, dan hasil bisnis.
Analisis Sentimen
Klasifikasi teks memungkinkan organisasi untuk mengelola merek mereka secara efektif di banyak saluran dengan mengekstraksi kata-kata tertentu yang mengindikasikan sentimen pelanggan. Menggunakan klasifikasi teks untuk analisis sentimen juga memungkinkan tim pemasaran untuk secara akurat memprediksi tren pembelian dengan data kualitatif.
Misalnya, Anda dapat menggunakan alat klasifikasi teks untuk menganalisis perilaku pelanggan dalam posting media sosial, survei, percakapan obrolan, atau sumber daya teks lainnya, serta merencanakan kampanye pemasaran yang sesuai.
Moderasi Konten
Bisnis mengembangkan audiens mereka di grup komunitas, media sosial, dan forum. Mengatur diskusi pengguna merupakan hal yang menantang ketika mengandalkan moderator manusia. Dengan model klasifikasi teks, Anda dapat secara otomatis mendeteksi kata, frasa, atau konten yang mungkin melanggar pedoman komunitas. Hal ini memungkinkan Anda untuk mengambil tindakan segera dan memastikan percakapan terjadi di lingkungan yang aman dan diatur dengan baik.
Manajemen Dokumen
Banyak organisasi menghadapi tantangan dalam memproses dan mengurutkan dokumen untuk mendukung operasi bisnis. Pengklasifikasi teks dapat mendeteksi informasi yang hilang, mengekstraksi kata kunci tertentu, dan mengidentifikasi hubungan semantik. Anda dapat menggunakan sistem klasifikasi teks untuk melabeli dan mengurutkan dokumen, seperti pesan, tinjauan, dan kontrak ke dalam kategorinya masing-masing.
Dukungan Pelanggan
Pelanggan mengharapkan respons yang tepat waktu dan akurat ketika mereka mencari bantuan dari tim dukungan. Pengklasifikasi teks yang ditenagai oleh machine learning memungkinkan tim dukungan pelanggan untuk merutekan permintaan yang masuk ke personel yang tepat. Misalnya, pengklasifikasi teks mendeteksi pertukaran kata dalam tiket dukungan dan mengirimkan permintaan tersebut ke departemen garansi.
Apa Saja Pendekatan untuk Klasifikasi Teks?
Klasifikasi teks telah berkembang pesat sebagai bagian dari pemrosesan bahasa alami. Kami membagikan beberapa pendekatan yang digunakan oleh para rekayasawan machine learning untuk mengklasifikasikan data teks.
Inferensi Bahasa Alami
Inferensi bahasa alami menentukan hubungan antara hipotesis dan premis dengan melabelinya sebagai keterlibatan, kontradiksi, atau netral. Keterlibatan menggambarkan hubungan logis antara premis dan hipotesis, sementara kontradiksi menunjukkan keterputusan hubungan antara entitas tekstual. Netral diterapkan saat tidak ditemukan adanya keterlibatan atau kontradiksi.
Misalnya, pertimbangkan premis berikut:
Tim kami adalah pemenang kejuaraan sepak bola.
Berikut cara hipotesis yang berbeda akan ditandai oleh pengklasifikasi inferensi bahasa alami.
-
Keterlibatan: Tim kami suka berolahraga.
-
Kontradiksi: Kami adalah orang yang tidak berolahraga.
-
Netral: Kami muncul sebagai juara sepak bola.
Pemodelan Bahasa Probabilistik
Pemodelan bahasa probabilistik adalah pendekatan statistik yang digunakan model bahasa untuk memprediksi kata berikutnya ketika diberikan urutan kata. Dengan pendekatan ini, model memberikan nilai probabilistik untuk setiap kata dan menghitung kemungkinan kata-kata berikutnya. Ketika diterapkan pada klasifikasi teks, pemodelan bahasa probabilistik mengategorikan dokumen berdasarkan frasa tertentu yang ditemukan dalam teks.
Penyematan Kata
Penyematan kata adalah teknik yang menerapkan representasi numerik ke kata-kata yang menangkap hubungan semantiknya. Penyematan kata adalah padanan numerik dari sebuah kata. Algoritma machine learning tidak dapat menganalisis teks secara efisien dalam bentuk aslinya. Dengan penyematan kata, algoritma pemodelan bahasa dapat membandingkan teks yang berbeda berdasarkan penyematannya.
Untuk menggunakan penyematan kata, Anda harus melatih model pemrosesan bahasa alami (NLP). Selama pelatihan, model memberikan kata-kata terkait dengan representasi numerik yang diposisikan secara dekat dalam ruang multidimensi yang dikenal sebagai semantik vektor.
Misalnya, ketika membuat vektor teks dengan penyematan, Anda akan menyadari bahwa anjing dan kucing lebih dekat satu sama lain dalam ruang vektor dua dimensi daripada tomat, orang, dan batu. Anda dapat menggunakan semantik vektor untuk mengidentifikasi teks yang mirip dalam data yang tidak dikenal dan memprediksi frasa berikutnya. Pendekatan ini sangat membantu dalam klasifikasi sentimen, pengorganisasian dokumen, dan tugas klasifikasi teks lainnya.
Model Bahasa Besar
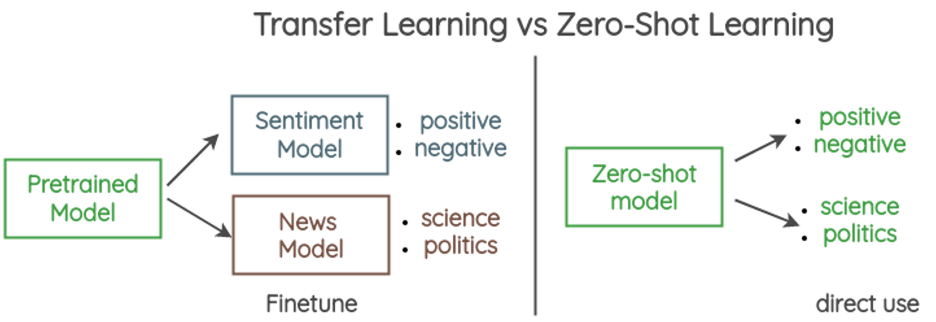
Model bahasa besar (LLM) adalah algoritma deep learning yang dilatih pada volume data teks yang besar. Model tersebut didasarkan pada arsitektur transformator, jaringan neural dengan banyak lapisan tersembunyi yang mampu memproses data teks secara paralel. Model bahasa besar lebih kuat daripada model yang lebih sederhana dan unggul dalam berbagai tugas pemrosesan bahasa alami, termasuk klasifikasi teks.
Tidak seperti pendahulunya, model bahasa besar dapat mengklasifikasikan teks tanpa pelatihan sebelumnya. Model tersebut menggunakan klasifikasi zero-shot, suatu metode yang memungkinkan model untuk mengategorikan data teks yang tidak terlihat ke dalam kategori yang sudah ditentukan sebelumnya. Misalnya, Anda bisa men-deploy model klasifikasi teks zero-shot pada Amazon Sagemaker Jumpstart untuk mengurutkan posting resolusi tahun baru ke dalam kelas karier, kesehatan, keuangan, dan kelas lainnya.
Bagaimana Anda Mengevaluasi Performa Klasifikasi Teks?
Sebelum Anda men-deploy pengklasifikasi teks untuk aplikasi bisnis, Anda harus mengevaluasinya untuk memastikan bahwa pengklasifikasi tersebut tidak mengalami underfitting. Underfitting adalah fenomena di mana algoritma machine learning beperforma baik dalam pelatihan, tetapi gagal mengklasifikasikan data di dunia nyata secara akurat. Untuk mengevaluasi model klasifikasi teks, kami menggunakan metode validasi silang.
Validasi Silang
Validasi silang adalah teknik evaluasi model yang membagi data pelatihan ke dalam grup-grup yang lebih kecil. Setiap grup kemudian dibagi menjadi beberapa sampel untuk pelatihan dan validasi model. Model pertama kali dilatih dengan sampel yang dialokasikan dan diuji dengan sampel yang tersisa. Kemudian, kami membandingkan hasil model dengan hasil anotasi dari manusia.
Kriteria Penilaian
Kami dapat mengevaluasi model klasifikasi teks dari penilaian pada beberapa kriteria.
-
Akurasi menjelaskan jumlah prediksi yang benar yang dibuat oleh pengklasifikasi teks dibandingkan dengan total prediksi.
-
Presisi mencerminkan kemampuan model untuk secara konsisten memprediksi kelas tertentu dengan benar. Pengklasifikasi teks akan menjadi lebih tepat jika menghasilkan lebih sedikit positif palsu.
-
Recall mengukur konsistensi model dalam keberhasilan memprediksi kelas yang tepat dibandingkan dengan semua prediksi positif.
-
Skor F1 menghitung rata-rata harmonik dari presisi dan recall untuk memberikan gambaran umum yang seimbang mengenai akurasi model.
Bagaimana Anda Mengimplementasikan Klasifikasi Teks?
Anda dapat membangun, melatih, dan men-deploy model klasifikasi teks dengan mengikuti langkah-langkah berikut.
Kurasi Set Data Pelatihan
Mempersiapkan set data berkualitas tinggi penting saat melatih atau menyempurnakan model bahasa untuk klasifikasi teks. Set data yang beragam dan berlabel memungkinkan model untuk belajar mengidentifikasi kata, frasa, atau pola tertentu dan kategori masing-masing secara efisien.
Siapkan Set Data
Model machine learning tidak dapat belajar dari set data mentah. Oleh karena itu, Anda harus membersihkan dan menyiapkan set data dengan metode prapemrosesan seperti tokenisasi. Tokenisasi membagi setiap kata atau kalimat menjadi bagian-bagian yang lebih kecil yang disebut token.
Setelah tokenisasi, Anda harus menghapus data redundan, duplikat, dan abnormal dari set data pelatihan karena dapat memengaruhi performa model. Kemudian Anda membagi set data menjadi data pelatihan dan validasi.
Latih Model Klasifikasi Teks
Pilih dan latih model bahasa dengan set data yang disiapkan. Selama pelatihan, model belajar dari set data beranotasi dan mencoba mengklasifikasikan teks ke dalam kategorinya masing-masing. Pelatihan selesai saat model secara konsisten memberikan hasil yang sama.
Evaluasi dan Optimalkan
Nilai model dengan set data uji. Bandingkan presisi, akurasi, recall, dan skor F1 model dengan tolok ukur yang telah ditetapkan. Model yang telah dilatih mungkin memerlukan penyesuaian lebih lanjut untuk mengatasi masalah overfitting dan masalah performa lainnya. Optimalkan model hingga Anda mencapai hasil yang memuaskan.
Apa Saja Tantangan dalam Klasifikasi Teks?
Organisasi dapat menggunakan sumber daya klasifikasi teks komersial atau yang tersedia untuk umum untuk mengimplementasikan jaringan neural pengklasifikasi teks. Namun, data yang terbatas dapat membuat kurasi set data pelatihan menjadi tantangan di industri tertentu. Sebagai contoh, perusahaan layanan kesehatan mungkin memerlukan bantuan untuk mendapatkan set data medis guna melatih model klasifikasi.
Melatih dan menyempurnakan model machine learning membutuhkan biaya dan memakan waktu. Selain itu, model mungkin overfit atau underfit sehingga menyebabkan performa yang tidak konsisten dalam kasus penggunaan aktual.
Anda dapat membangun pengklasifikasi teks dengan pustaka machine learning sumber terbuka. Namun, Anda memerlukan pengetahuan machine learning khusus dan pengalaman pengembangan perangkat lunak selama bertahun-tahun untuk melatih, memprogram, serta mengintegrasikan pengklasifikasi dengan aplikasi korporasi.
Bagaimana AWS Dapat Membantu Persyaratan Klasifikasi Teks Anda?
Amazon Comprehend adalah layanan NLP yang menggunakan machine learning untuk mengungkap wawasan yang berharga dan koneksi dalam teks. API Klasifikasi Kustom memungkinkan Anda untuk membuat model klasifikasi teks kustom dengan mudah menggunakan label khusus bisnis tanpa perlu mempelajari ML.
Misalnya, organisasi dukungan pelanggan Anda dapat menggunakan Klasifikasi Kustom untuk mengategorikan permintaan masuk berdasarkan tipe masalah secara otomatis berdasarkan cara pelanggan mendeskripsikan masalahnya. Dengan model kustom Anda, memoderasi komentar situs web, melakukan triase umpan balik pelanggan, dan mengatur dokumen grup kerja menjadi lebih mudah.
Amazon SageMaker adalah layanan terkelola penuh untuk menyiapkan data dan membangun, melatih, serta men-deploy model ML untuk kasus penggunaan apa pun. Amazon SageMaker memiliki infrastruktur, alat, dan alur kerja terkelola penuh.
Dengan Amazon SageMaker JumpStart, Anda dapat mengakses model yang telah dilatih sebelumnya dan model fondasi (FM) serta mengustomisasinya untuk kasus penggunaan dengan data Anda. SageMaker JumpStart menyediakan solusi ujung ke ujung dengan sekali klik untuk banyak kasus penggunaan ML yang umum. Anda dapat menggunakannya untuk klasifikasi teks, peringkasan dokumen, pengenalan tulisan tangan, ekstraksi hubungan, pertanyaan dan jawaban, serta pengisian nilai yang hilang dalam catatan tabular.
Mulai Klasifikasi Teks di Amazon Web Services (AWS) dengan Membuat Akun Sekarang Juga.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages