AWS Storage Blog
Tag: AWS Command Line Interface (AWS CLI)
Zero-downtime Amazon S3 Versioning: Architectural patterns for mission-critical workloads
Organizations delivering content on a global scale rely on distributed edge networks to cache and serve billions of requests daily. These architectures depend on highly aggressive Time-To-Live (TTL) configurations to maximize performance and minimize origin load. On a cache miss, the network falls through to the origin to retrieve the requested content. At this scale, […]
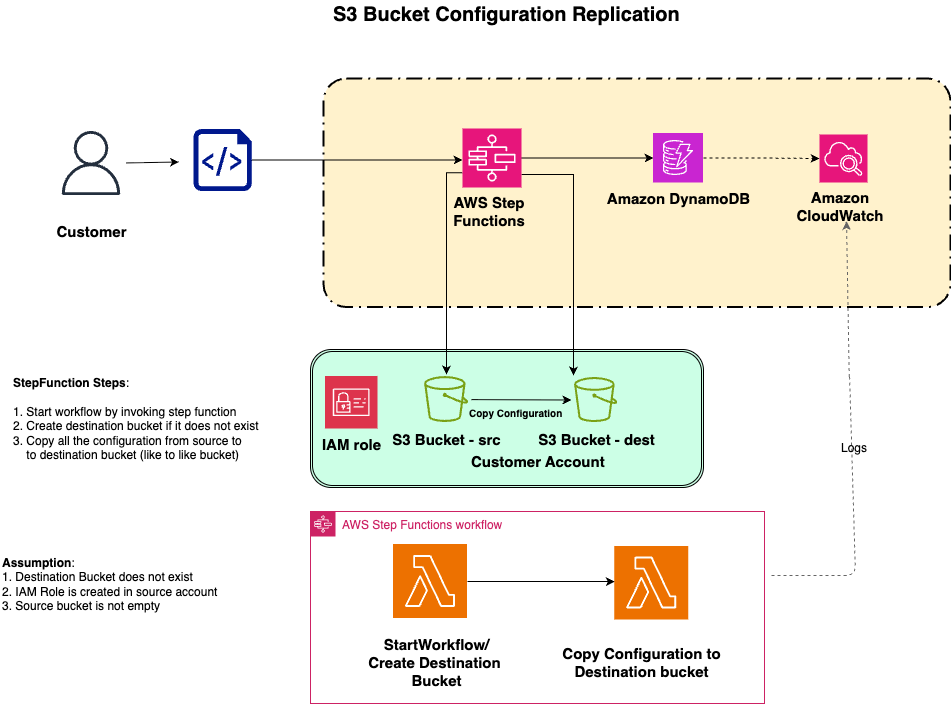
Replicate Amazon S3 bucket configurations across AWS Regions with AWS Step Functions
Many organizations operate thousands of Amazon S3 buckets in a single AWS Region, each with its own configuration accumulated over the years. Some were created manually in the AWS Management Console and others by scripts that are no longer actively maintained, provisioned by different business units with their own policies, lifecycle rules, encryption, and tags. […]

Query Amazon S3 access logs instantly with CloudWatch and S3 Tables
Knowing who accessed your data, when, and how is the foundation for security investigations, compliance audits, cost attribution, and performance troubleshooting. Detailed access logs capture every request: who made it, which resource was accessed, and what response was returned. In practice, though, they arrive as semi-structured records spread across different locations. Turning them into actionable […]
Scalable cross-cloud data migration to Amazon S3 with distributed rclone
Migrating petabytes of data across cloud providers is one of the most operationally demanding tasks an organization can take on. At this scale, simple transfer approaches break down. Teams lose track of what has been copied and what has failed. Transfers stall and require constant manual intervention to restart. In some cases, teams need to […]

Implement single-exchange tokens for short-lived Amazon S3 presigned URLs with Terraform
Organizations across industries use signed URLs to grant temporary, credential-less access to private resources such as receipts, medical or financial records, legal files, or confidential reports. However, signed URLs can be reused by anyone until they expire, creating security risks if a URL is shared or inadvertently disclosed. This risk can be mitigated by vending […]

Building automated AWS Regional availability checks with Amazon S3
Every day, organizations expand into new markets, migrate critical workloads across geographies, and build systems that need to operate reliably in multiple locations. At the root of these efforts is a simple question: “What can I deploy, and where?” The answer shapes important architecture decisions, from which AWS Regions to expand into, to how you […]

How Tavily reduced AI search caching costs by 95% with Amazon S3 Express One Zone
Tavily is an AI infrastructure company building the web access layer for agents and large language models (LLMs). The company provides developer-friendly APIs that enable real-time, structured retrieval from the web. Their mission is to make information instantly accessible for intelligent systems, and they’re trusted by thousands of leading research, commercial AI teams, and enterprises […]

Applying Amazon S3 Object Lock at scale for petabytes of existing data
Organizations with petabytes of data in the cloud need a way to apply immutable storage protections to data that’s already been stored—whether for regulatory compliance or cyber resilience. Although you can enable write-once-read-many (WORM) controls for newly created storage, applying these protections to existing enterprise data at scale requires a systematic approach. Regulated industries have […]

Derive intelligent storage insights using S3 Metadata and Model Context Protocol (MCP)
Organizations face mounting challenges in managing and operationalizing their ever-growing data assets for machine learning and analytics workflows. When dealing with billions and trillions of objects, teams struggle to find what data they have and how to efficiently find specific datasets. Without proper data discovery and metadata management, teams spend valuable time searching for relevant […]

Accelerating Amazon S3 Batch Operations at scale with on-demand manifest generation
Modern enterprises routinely manage billions of objects across their cloud storage environments, needing efficient bulk operations for disaster recovery, compliance management, data transfer, and cost optimization. Performing these operations manually or through custom scripts becomes impractical at scale, often creating operational bottlenecks when time-sensitive actions are necessary. Organizations frequently need to identify and process specific […]