AWS Database Blog
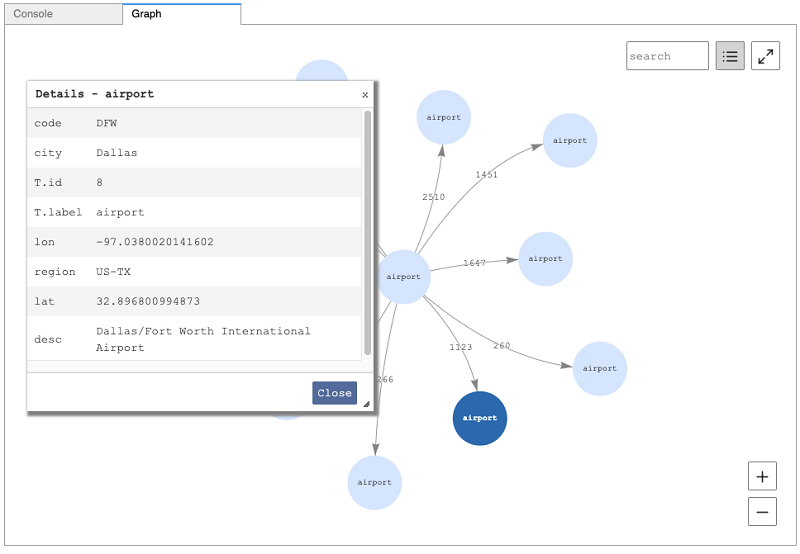
Visualize query results using the Amazon Neptune workbench
In this post, we look at the new visualization features recently added to the Amazon Neptune workbench and released on August 12, 2020. These additional capabilities allow you to produce an interactive graph diagram representing the results of your Gremlin and SPARQL queries. We look at some Gremlin-specific features and then do the same for SPARQL. Finally, we look at some of the more advanced ways you can modify the visualizations. As a sidenote, this entire post was produced using the workbench.
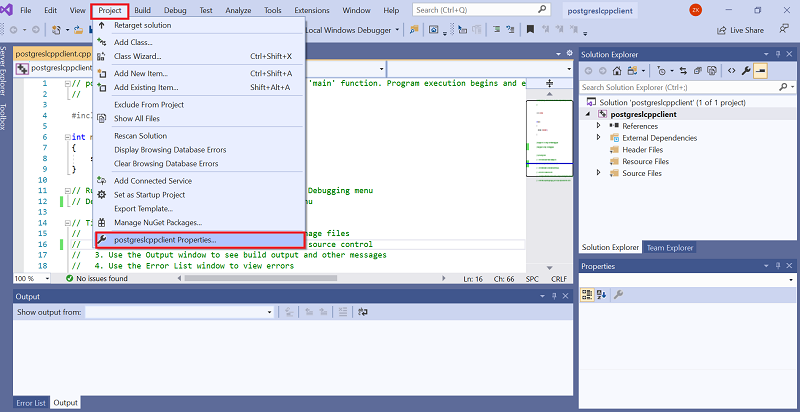
SSL connection to an Amazon Aurora PostgreSQL database from a C++ application using Visual Studio
Your organization may require you to connect to databases using secure SSL connections so all traffic communicating with the database is encrypted. In this post, we provide guidance on how to connect to an Amazon Aurora PostgreSQL database from a C++ application using the libpq library. We show you how to enforce SSL connections to your Aurora PostgreSQL database and connect to this from a C++ application using a secured SSL connection. You can also apply the same principles to an Amazon RDS for PostgreSQL database.
Accelerating Nylas’s feature development with AWS Data Lab
This is a guest post by David Ting, VP of Engineering at Nylas. In their own words, Nylas is a pioneer and leading provider of universal communications APIs that allow developers to quickly connect their applications to every email, calendar, or contacts provider in the world. Over 26,000 developers around the globe use the Nylas […]
Amazon RDS for SQL Server now supports SQL Server 2019
Amazon RDS for SQL Server now supports Microsoft SQL Server 2019 for Express, Web, Standard, and Enterprise Editions. You can use SQL Server 2019 features such as Accelerated Database Recovery, Intelligent Query Processing, Intelligent Performance, Monitoring improvements, and Resumable Online Index creations. The purpose of this post is to: Summarize the new features in SQL […]

Benefitting from SPARQL 1.1 Federated Queries with Amazon Neptune
In this post, I show you how to use SPARQL 1.1 Federated Query in Neptune to get data about soccer teams in the UK from an external dataset, DBpedia (a well-known public dataset of Wikipedia data). Using the DBpedia publicly accessible SPARQL endpoint, I link the data from DBpedia to data that I add to the Neptune cluster.

Building a blockchain application in Java using Amazon Managed Blockchain
This post demonstrates how to set up a blockchain application written in Java to read and write data to Managed Blockchain using the Fabric Java SDK. The Java SDK allows customers with applications written in Java to integrate blockchain support with their existing codebase. This makes it easier to handle rich data structures and complex business logic before writing records to the blockchain. You can also integrate Managed Blockchain using the Fabric Node.js SDK. For more information, see Building serverless blockchain application with Fabric Node.js SDK.

Implementing table partitioning in Oracle Standard Edition: Part 1
Oracle table partitioning is a commonly used feature to manage large tables and improve SELECT query performance. Oracle partitioning is only available in the Oracle EE Extra cost option. This post demonstrates how to implement a partitioning feature for tables in Oracle Standard Edition (Oracle SE) using a single view accessing multiple sub-tables and the INSTEAD OF trigger.

Analyzing performance management in Oracle SE using Amazon RDS for Oracle
Organizations are aggressively adopting cloud as a standard and actively evaluating their database needs. Amazon RDS for Oracle is a managed service that makes it easy to quickly create Oracle Database instances, enabling you to migrate existing on-premises workloads to the cloud. Migration from on-premises Oracle Database to Amazon RDS for Oracle is quick because […]

Managing your SQL plan in Oracle SE with Amazon RDS for Oracle
Organizations are aggressively adopting the cloud as the standard and actively evaluating their database needs. Amazon RDS for Oracle is a managed service that makes it easy to quickly create Oracle Database instances, enabling you to migrate existing on-premises workloads to the cloud. Migration from on-premises Oracle Database to Amazon RDS for Oracle is quick […]

Profiling slow-running queries in Amazon DocumentDB (with MongoDB compatibility)
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without having to worry about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data. AWS built Amazon DocumentDB to uniquely solve your challenges around availability, performance, reliability, durability, scalability, backup, and more. In doing so, we built several tools, like the profiler, to help you run analyze your workload on Amazon DocumentDB. The profiler gives you the ability to log the time and details of slow-running operations on your cluster. In this post, we show you how to use the profiler in Amazon DocumentDB to analyze slow-running queries to identify bottlenecks and improve individual query performance and overall cluster performance.