AWS Database Blog
Category: Expert (400)

Navigating backup and recovery options for Oracle Database@AWS
Oracle Database@AWS (ODB@AWS) delivers Oracle Exadata infrastructure, managed by Oracle Cloud Infrastructure (OCI), directly within Amazon Web Services (AWS) data centers. In this post, we walk you through the backup and recovery options available for ODB@AWS services: Oracle Exadata Database Service on Dedicated Infrastructure (ExaDB-D) and Oracle Autonomous AI Database on Dedicated Exadata Infrastructure (ADB-D).

Optimize full-text search in Amazon RDS for MySQL and Amazon Aurora MySQL
In this post, we show you how to optimize full-text search (FTS) performance in Amazon RDS for MySQL and Amazon Aurora MySQL-Compatible Edition through proper maintenance and monitoring. We discuss why FTS indexes require regular maintenance, common issues that can arise, and best practices for keeping your FTS-enabled databases running smoothly.
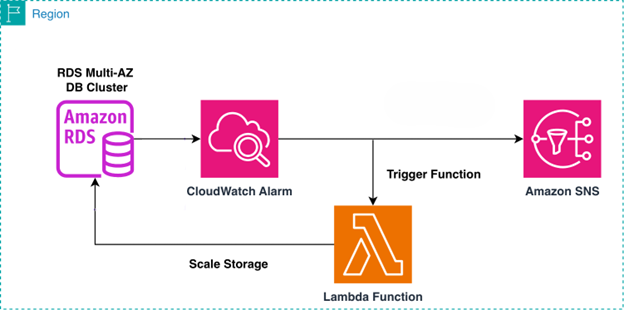
Automatically scale storage for Amazon RDS Multi-AZ DB clusters using AWS Lambda
In this post, we walk you through building an automated storage scaling solution for Amazon RDS Multi-AZ clusters with two readable standbys. We use AWS Lambda to execute scaling logic, Amazon CloudWatch to detect and alarm on storage thresholds, and Amazon SNS to deliver timely notifications. This combination provides event-driven automation, native AWS integration, and operational visibility without requiring third-party tooling.

Synchronizing a Backup on-premises Db2 Server with Amazon RDS for Db2
In this post, we provide guidance on implementing a hybrid architecture where a self-managed Db2 instance remains synchronized with Amazon RDS for Db2 via continuous archive log application, ensuring organizations maintain strategic deployment options without compromising the advantages of cloud-native managed services.
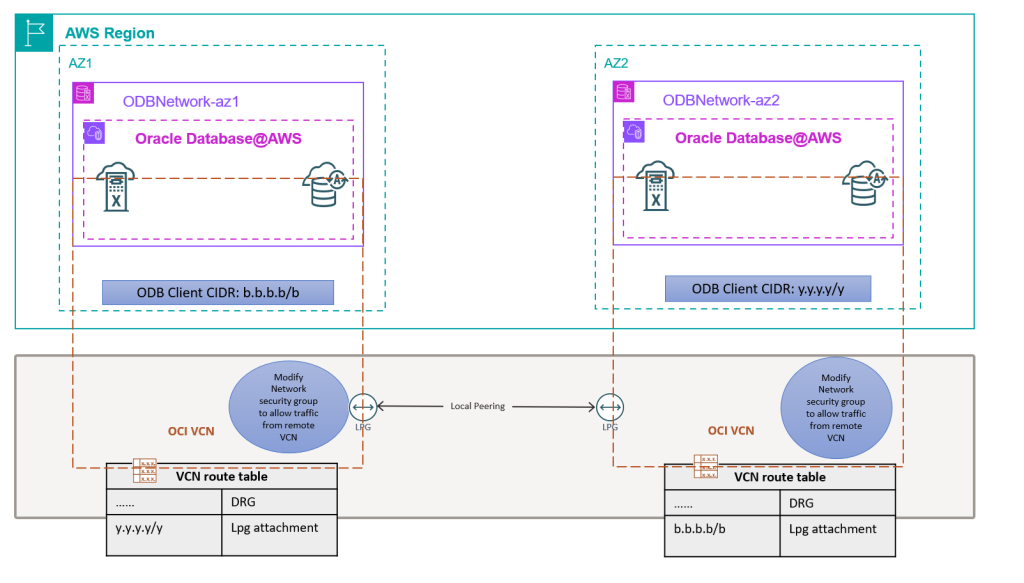
Well-Architected design for resiliency with Oracle Database@AWS
Oracle Database@AWS delivers enterprise-grade database capabilities through database services that use Oracle Exadata infrastructure managed by Oracle Cloud Infrastructure (OCI) within Amazon Web Services (AWS) data centers. High availability (HA) and disaster recovery (DR) options are important aspects to consider when migrating or deploying your critical database in Oracle Database@AWS to help make sure the architecture can meet the service level agreement (SLA) of the application. This post will help you implement and maintain Data Guard configurations that follow Oracle’s Maximum Availability Architecture (MAA) best practices and the AWS Well-Architected Framework. We will show how to select the right network architecture and configure Data Guard associations for both cross-AZ and cross-Region deployments, making sure your applications maintain seamless connectivity during role transitions.

Resilience testing on Amazon ElastiCache with AWS Fault Injection Service
In this post, we guide you on how to run resilience tests on Amazon ElastiCache using AWS Fault Injection Service and how you can use it to strengthen the resilience strategy of your application.

Auto Analyze in Aurora DSQL: Managed optimizer statistics in a multi-Region database
In this post, we give insights into Aurora DSQL Auto Analyze, a probabilistic and de-facto stateless method to automatically compute DSQL optimizer statistics. Users who are familiar with PostgreSQL will appreciate the similarity to autovacuum analyze.

Everything you don’t need to know about Amazon Aurora DSQL: Part 4 – DSQL components
Amazon Aurora DSQL employs an active-active distributed database design, wherein all database resources are peers and serve both write and read traffic within a Region and across Regions. This design facilitates synchronous data replication and automated zero data loss failover for single and multi-Region Aurora DSQL clusters. In this post, I discuss the individual components and the responsibilities of a multi-Region distributed database to provide an ACID-compliant, strongly consistent relational database.

Everything you don’t need to know about Amazon Aurora DSQL: Part 3 – Transaction processing
In this third post of the series, I examine the end-to-end processing of the two transaction types in Aurora DSQL: read-only and read-write. Amazon Aurora DSQL doesn’t have write-only transactions, since it’s imperative to verify the table schema or ensure the uniqueness of primary keys on each change – which results them being read-write transactions as well.

Accelerate generative AI use cases with Amazon Bedrock and Oracle Database@AWS
In this post, we walk through the steps of integrating Oracle Database@AWS (ODB@AWS) with Amazon Bedrock for by creating a RAG assistant application using an Amazon Titan embedding model in Amazon Bedrock and vectors stored in Oracle AI Database 26ai.